
Có nhiều thuật toán khác nhau được Hệ điều hành thực hiện để tìm ra các lỗ hổng trong danh sách được liên kết và phân bổ chúng cho các quy trình.
Các bài viết liên quan:
Thuật toán Partitioning trong hệ điều hành
First Fit Algorithm
Thuật toán First Fit quét danh sách được liên kết và bất cứ khi nào nó tìm thấy lỗ đầu tiên đủ lớn để lưu trữ một quy trình, nó sẽ dừng quét và tải quy trình vào lỗ đó. Thủ tục này tạo ra hai phân vùng. Trong số chúng, một phân vùng sẽ là một lỗ hổng trong khi phân vùng khác sẽ lưu trữ tiến trình.
Thuật toán First Fit duy trì danh sách liên kết theo thứ tự tăng dần của chỉ mục bắt đầu. Đây là thuật toán đơn giản nhất để thực hiện trong số tất cả các thuật toán và tạo ra lỗ hổng lớn hơn so với các thuật toán khác.
Next Fit Algorithm
Thuật toán Next Fit tương tự như thuật toán First Fit ngoại trừ thực tế là, Next fit quét danh sách được liên kết từ nút mà trước đó nó đã phân bổ một lỗ.
Next fit không quét toàn bộ danh sách, nó bắt đầu quét danh sách từ nút tiếp theo. Ý tưởng đằng sau sự phù hợp tiếp theo là thực tế là danh sách đã được quét một lần, do đó xác suất tìm thấy lỗ hổng lớn hơn trong phần còn lại của danh sách.
Các thử nghiệm về thuật toán đã chỉ ra rằng lần phù hợp tiếp theo không tốt hơn lần phù hợp đầu tiên. Vì vậy, nó không được sử dụng ngày nay trong hầu hết các trường hợp.
Best Fit Algorithm
Thuật toán Best Fit cố gắng tìm ra lỗ nhỏ nhất có thể trong danh sách có thể đáp ứng yêu cầu kích thước của quy trình.
Sử dụng Best Fit có một số nhược điểm.
- Nó chậm hơn vì nó quét toàn bộ danh sách mọi lúc và cố gắng tìm ra lỗ nhỏ nhất có thể đáp ứng yêu cầu của quy trình.
- Do thực tế là sự khác biệt giữa kích thước toàn bộ và kích thước quy trình là rất nhỏ, các lỗ được tạo ra sẽ nhỏ đến mức nó không thể được sử dụng để tải bất kỳ quy trình nào và do đó nó vẫn vô dụng.
Mặc dù thực tế là tên của thuật toán là phù hợp nhất, nhưng nó không phải là thuật toán tốt nhất trong số tất cả.
Worst Fit Algorithm
Thuật toán phù hợp nhất sẽ quét toàn bộ danh sách mọi lúc và cố gắng tìm ra lỗ hổng lớn nhất trong danh sách có thể đáp ứng yêu cầu của quy trình.
Mặc dù thực tế là thuật toán này tạo ra các lỗ lớn hơn để tải các quy trình khác, nhưng đây không phải là cách tiếp cận tốt hơn do thực tế là nó chậm hơn vì nó tìm kiếm toàn bộ danh sách lặp đi lặp lại.
Quick Fit Algorithm
Thuật toán phù hợp nhanh đề xuất duy trì các danh sách khác nhau về các kích thước được sử dụng thường xuyên. Mặc dù trên thực tế, nó không phải là gợi ý vì quy trình này tốn rất nhiều thời gian để tạo các danh sách khác nhau và sau đó sử dụng các lỗ hổng để tải một quy trình.
Thuật toán phù hợp đầu tiên là thuật toán tốt nhất trong số tất cả vì
- Nó mất ít thời gian hơn so với các thuật toán khác.
- Nó tạo ra các lỗ lớn hơn có thể được sử dụng để tải các quy trình khác sau này.
- Nó là dễ dàng nhất để thực hiện.
Ví dụ về best fit và first fit
Theo quan điểm của GATE, Số lượng trên trang phục vừa vặn nhất và vừa vặn nhất đang được hỏi thường xuyên trong 1 lần đánh dấu. Chúng ta hãy xem xét một trong những được đưa ra như dưới đây.
Các yêu cầu quy trình được đưa ra như;
25 K, 50 K, 100 K, 75 K

Xác định thuật toán có thể đáp ứng yêu cầu này một cách tối ưu.
- Thuật toán First Fit
- Thuật toán first Fit
- Cả hai đều không
- Cả hai
Trong câu hỏi, có năm phân vùng trong bộ nhớ. 3 phân vùng đang có các quy trình bên trong chúng và hai phân vùng là lỗ.
Nhiệm vụ của chúng tôi là kiểm tra thuật toán có thể đáp ứng yêu cầu một cách tối ưu.
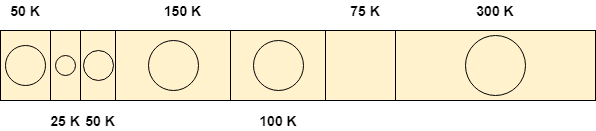
Sử dụng thuật toán First Fit
Hãy xem, thuật toán phù hợp đầu tiên hoạt động như thế nào đối với vấn đề này.
Yêu cầu 25 K
Thuật toán quét danh sách cho đến khi nó nhận được lỗ đầu tiên đủ lớn để đáp ứng yêu cầu 25 K. K được sản xuất dưới dạng lỗ.

Yêu cầu 50 K
Yêu cầu 50 K có thể được thực hiện bằng cách phân bổ phân vùng thứ ba có kích thước 50 K cho quy trình. Không có dung lượng trống nào được tạo ra là không gian trống.

Yêu cầu 100 K
Yêu cầu 100 K có thể được đáp ứng bằng cách sử dụng phân vùng thứ năm có kích thước 175 K. Trong số 175 K, 100 K sẽ được phân bổ và 75 K còn lại sẽ ở đó dưới dạng một lỗ.
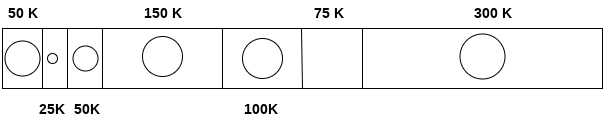
Yêu cầu 75 K
Vì chúng ta đang có một phân vùng trống 75 K, do đó chúng ta có thể phân bổ nhiều không gian đó cho quá trình yêu cầu chỉ 75 K dung lượng.
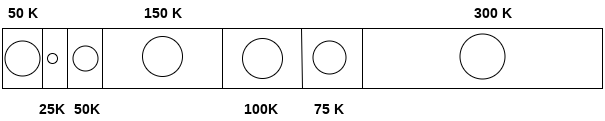
Sử dụng thuật toán phù hợp đầu tiên, chúng tôi đã hoàn thành toàn bộ yêu cầu một cách tối ưu và không còn dung lượng vô ích.
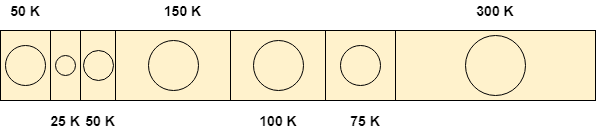
Hãy xem, thuật toán Best Fit hoạt động như thế nào đối với vấn đề này.
Sử dụng thuật toán phù hợp nhất
Yêu cầu 25 K
Để phân bổ không gian 25 K bằng cách sử dụng phương pháp phù hợp nhất, cần phải quét toàn bộ danh sách và sau đó chúng tôi thấy rằng phân vùng 75 K là miễn phí và là phân vùng nhỏ nhất trong số tất cả, có thể đáp ứng nhu cầu của quá trình.
Do đó 25 K trong số 75 K phân vùng tự do đó được phân bổ cho quá trình và 5o K còn lại được tạo ra dưới dạng lỗ.
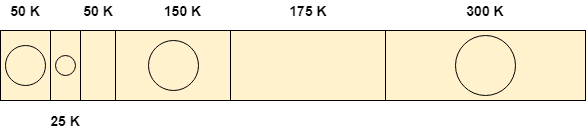
Yêu cầu 50 K
Để đáp ứng nhu cầu này, chúng tôi sẽ quét lại toàn bộ danh sách và sau đó tìm không gian trống 50 K phù hợp chính xác với nhu cầu. Do đó, nó sẽ được phân bổ cho quá trình.
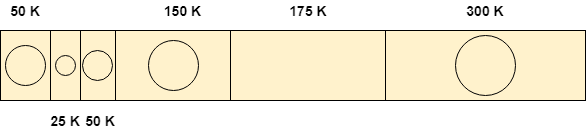
Yêu cầu 100 K
Cần 100 K là đủ gần với khoảng trống 175 K. Thuật toán quét toàn bộ danh sách và sau đó phân bổ 100 K trên 175 K từ phân vùng trống thứ 5.
Yêu cầu 75 K
Yêu cầu 75 K sẽ nhận được không gian 75 K từ phân vùng trống thứ 6 nhưng thuật toán sẽ quét toàn bộ danh sách trong quá trình thực hiện quyết định này.
Bằng cách theo dõi cả hai thuật toán, chúng tôi nhận thấy rằng cả hai thuật toán đều hoạt động tương tự như hầu hết các thuật toán còn tồn tại trong trường hợp này.
Cả hai đều có thể đáp ứng nhu cầu của các quy trình nhưng tuy nhiên, thuật toán phù hợp nhất sẽ quét đi quét lại danh sách, điều này mất rất nhiều thời gian.
Do đó, nếu bạn hỏi tôi rằng thuật toán nào hoạt động theo cách tối ưu hơn thì chắc chắn đó sẽ là thuật toán First Fit .
Do đó, đáp án trong trường hợp này là A.

