
Mạng Bayesian, một công cụ mạnh mẽ trong lý thuyết xác suất, được sử dụng rộng rãi để mô hình hóa các mối quan hệ phụ thuộc và sự không chắc chắn trong nhiều lĩnh vực, bao gồm cả phân tích dữ liệu. Chúng kết hợp kiến thức chuyên môn và dữ liệu quan sát được để đưa ra dự đoán hoặc đánh giá sự không chắc chắn của các biến. Trong ngành chăm sóc sức khỏe, tài chính, nghiên cứu thị trường và nhiều lĩnh vực khác, mạng Bayesian đã chứng minh giá trị của mình trong việc giải quyết các vấn đề phức tạp.
Mục tiêu của bài viết này là cung cấp một hướng dẫn chi tiết về cách sử dụng R, một ngôn ngữ lập trình và môi trường phần mềm miễn phí phổ biến cho phân tích thống kê và đồ họa, để xây dựng và áp dụng mạng Bayesian. R không chỉ mạnh mẽ và linh hoạt mà còn có một cộng đồng người dùng đông đảo và nhiều gói phần mềm hỗ trợ, làm cho nó trở thành một lựa chọn tuyệt vời cho việc phát triển mạng Bayesian. Bài viết sẽ hướng dẫn từ cơ bản đến nâng cao, giúp người mới bắt đầu có thể tiếp cận và áp dụng mạng Bayesian vào phân tích dữ liệu của họ một cách hiệu quả.
Giới thiệu về Mạng Bayesian
Mạng Bayesian, còn được biết đến với tên gọi mạng tin cậy, là một mô hình xác suất đồ thị mô tả một tập hợp các biến ngẫu nhiên và sự phụ thuộc có điều kiện giữa chúng thông qua một đồ thị có hướng. Trong cấu trúc của mạng Bayesian, các nút đại diện cho các biến ngẫu nhiên, có thể là bất kỳ thứ gì từ sự kiện đến các đặc điểm hay kết quả cụ thể. Các cạnh, hoặc các đường nối, biểu thị mối quan hệ phụ thuộc có điều kiện giữa các biến, cho phép mô hình thể hiện cách mà sự hiểu biết về một biến có thể ảnh hưởng đến sự hiểu biết của chúng ta về biến khác.
Mỗi nút trong mạng Bayesian được liên kết với một phân phối xác suất có điều kiện, mô tả xác suất của biến đó dựa trên các giá trị của các biến mà nó phụ thuộc. Điều này cho phép mạng Bayesian mô hình hóa sự không chắc chắn và phụ thuộc một cách hiệu quả. Khi một hoặc nhiều biến (nút) trong mạng có giá trị được biết đến, mạng có thể được sử dụng để tính toán xác suất của các biến chưa biết, cho phép các nhà nghiên cứu và nhà phân tích dự đoán và đưa ra quyết định dựa trên thông tin có sẵn.
Mạng Bayesian là công cụ mạnh mẽ cho phân tích dữ liệu vì chúng có thể dễ dàng cập nhật và mở rộng khi thông tin mới được tiếp thu và tích hợp vào mô hình. Sự linh hoạt và khả năng mô hình hóa sự phụ thuộc và không chắc chắn làm cho mạng Bayesian trở thành một công cụ quan trọng trong nhiều lĩnh vực, từ chăm sóc sức khỏe đến tài chính và hơn thế nữa.
Ví dụ về Mạng Bayes trong R
Giả sử bạn muốn xác định khả năng cỏ bị ướt hoặc khô do sự xuất hiện của các mùa khác nhau.
Thời tiết có ba trạng thái: Nắng, Nhiều mây và Mưa . Có hai khả năng cho cỏ: Ướt hoặc khô.
Vòi phun nước có thể bật hoặc tắt. Nếu trời mưa, cỏ bị ướt nhưng nếu trời nắng, chúng ta có thể làm ướt cỏ bằng cách đổ nước từ vòi phun.
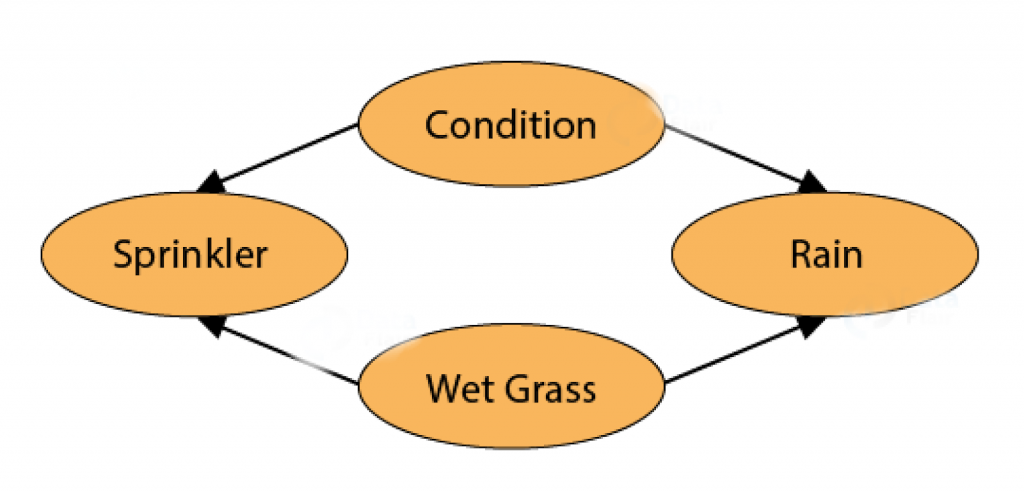
Khi xác suất của Mạng Bayes phản ánh thời tiết và bãi cỏ, thì BN có thể trả lời các câu hỏi như xác suất mưa hoặc vòi phun nước làm cho bãi cỏ ướt là bao nhiêu? Nếu xác suất mưa tăng lên, thì việc sử dụng vòi phun nước để tưới cỏ sẽ có tác động như thế nào?
Giả sử rằng cỏ ướt. Điều này có thể được góp phần bởi một trong hai lý do – Thứ nhất, trời mưa. Thứ hai, các vòi phun nước được bật. Sử dụng Quy tắc Baye, người ta có thể suy ra yếu tố góp phần nhiều nhất đối với cỏ ướt mà trong trường hợp này là do mưa.
Lập trình Mạng Bayesian trong R
Trong môi trường R, có nhiều gói phần mềm hỗ trợ việc xây dựng và làm việc với mạng Bayesian, giúp người dùng dễ dàng lập trình và áp dụng các mô hình phức tạp. Ba trong số các gói phổ biến nhất bao gồm bnlearn, gRain, và catnet.
- bnlearn: Đây là một gói R linh hoạt và mạnh mẽ cho việc học và phân tích mạng Bayesian.
bnlearnhỗ trợ học cấu trúc mạng từ dữ liệu, học phân phối xác suất có điều kiện, và thực hiện suy luận trong mạng Bayesian. Để cài đặtbnlearn, bạn có thể sử dụng lệnh sau trong R:
install.packages("bnlearn")- gRain: Gói
gRaintập trung vào suy luận trong mạng Bayesian và mạng quyết định đồ thị. Nó cung cấp công cụ để tạo ra, biểu diễn và thao tác với các mạng và thực hiện các phép suy luận có điều kiện. Để cài đặtgRain, bạn có thể sử dụng lệnh sau:
install.packages("gRain")- catnet: Gói
catnetđược thiết kế để phân tích và mô hình hóa mạng Bayesian phân loại. Nó cung cấp các công cụ cho việc học mạng và suy luận xác suất.catnetrất hữu ích trong các ứng dụng sinh học và y tế. Để cài đặtcatnet, sử dụng lệnh:
install.packages("catnet")Sau khi cài đặt, bạn có thể tải và sử dụng mỗi gói trong phiên làm việc của R bằng cách sử dụng lệnh library(), ví dụ:
library(bnlearn)
Mỗi gói này có những đặc điểm và chức năng riêng, phù hợp với các loại nhu cầu và ứng dụng khác nhau trong việc xây dựng và phân tích mạng Bayesian. Người dùng nên chọn gói phù hợp với mục tiêu cụ thể của dự án phân tích dữ liệu của họ.
Xây dựng một mô hình Mạng Bayesian
Xây dựng một mô hình Mạng Bayesian bao gồm hai bước chính: định nghĩa cấu trúc của mạng bằng cách xác định các nút và cạnh, và sau đó xác định phân phối xác suất có điều kiện (CPD) cho mỗi nút.
Định nghĩa mạng:
- Mỗi nút trong mạng Bayesian đại diện cho một biến ngẫu nhiên, có thể là một thuộc tính, một đặc điểm, hoặc một kết quả cụ thể. Việc xác định nút bắt đầu từ việc hiểu rõ về dữ liệu và mối quan hệ bạn muốn mô hình hóa.
- Cạnh trong mạng biểu diễn sự phụ thuộc có điều kiện giữa các biến. Một cạnh từ nút A đến nút B cho thấy A có ảnh hưởng đến B, hay B phụ thuộc vào A. Việc xác định cạnh dựa trên kiến thức chuyên môn hoặc thông qua quá trình học từ dữ liệu.
Xác định và nhập CPD:
- Sau khi đã xác định cấu trúc của mạng, bước tiếp theo là xác định CPD cho mỗi nút. CPD cho một nút cụ thể mô tả xác suất của nút đó dựa trên các giá trị của nút cha (hoặc các nút mà nó phụ thuộc).
- CPD có thể được xác định dựa trên dữ liệu lịch sử, nghiên cứu từ trước, hoặc thông qua quá trình học máy từ dữ liệu. Trong R, bạn có thể sử dụng các hàm từ các gói như
bnlearnđể nhập và thiết lập CPD, thường dưới dạng bảng xác suất hoặc thông qua việc chỉ định phân phối thống kê.
Ví dụ, để tạo một mạng với bnlearn, bạn có thể định nghĩa mạng và nhập CPD như sau:
library(bnlearn)
# Tạo một cấu trúc mạng
network <- model2network("[A][B|A][C|A:B]")
# Xác định CPD cho mỗi nút
cpd_A <- matrix(c(0.7, 0.3), ncol = 2, dimnames = list(NULL, c("a", "not_a")))
cpd_B <- matrix(c(0.1, 0.9, 0.8, 0.2), ncol = 2, dimnames = list("a" = c("b", "not_b"), "not_a" = c("b", "not_b")))
cpd_C <- array(c(0.8, 0.2, 0.6, 0.4, 0.3, 0.7, 0.9, 0.1), dim = c(2, 2, 2), dimnames = list("a" = c("c", "not_c"), "b" = c("c", "not_c"), "not_a" = c("c", "not_c"), "not_b" = c("c", "not_c")))
# Thiết lập CPD cho mạng
bn <- custom.fit(network, dist = list(A = cpd_A, B = cpd_B, C = cpd_C))Quá trình này giúp xác định một mô hình Mạng Bayesian hoàn chỉnh, sẵn sàng cho việc suy luận và dự đoán.
Huấn luyện và đánh giá mạng Bayesian
Huấn luyện mạng Bayesian là một quá trình quan trọng để đảm bảo rằng mô hình phản ánh chính xác mối quan hệ giữa các biến và có thể đưa ra dự đoán chính xác. Quá trình này bao gồm hai bước chính: học cấu trúc và học tham số.
Học cấu trúc:
- Học cấu trúc của mạng Bayesian liên quan đến việc xác định mạng lưới các biến và sự phụ thuộc giữa chúng, tức là xác định cách các nút (biến) được kết nối với nhau thông qua các cạnh (sự phụ thuộc).
- Cách tiếp cận này có thể được thực hiện một cách thủ công dựa trên kiến thức chuyên môn hoặc thông qua các kỹ thuật học máy, sử dụng dữ liệu để tự động xác định cấu trúc tối ưu. Trong R, các gói như
bnlearncung cấp các hàm nhưhc,tabu,mmhc, v.v., để học cấu trúc mạng từ dữ liệu.
Học tham số:
- Sau khi cấu trúc mạng được xác định, bước tiếp theo là học tham số, tức là xác định phân phối xác suất có điều kiện (CPD) cho mỗi nút dựa trên dữ liệu. Điều này bao gồm việc ước lượng xác suất để mô hình có thể đưa ra dự đoán chính xác về các biến khi được cung cấp thông tin mới.
- R cung cấp các công cụ để ước lượng các tham số này, như hàm
bn.fittrong góibnlearn, cho phép bạn dễ dàng điều chỉnh mô hình dựa trên dữ liệu quan sát được.
Đánh giá hiệu suất và độ chính xác của mạng:
- Để đánh giá hiệu suất và độ chính xác của mạng Bayesian, có thể sử dụng các phương pháp như cross-validation hoặc tập dữ liệu giữ lại để kiểm tra khả năng dự đoán của mạng trên dữ liệu chưa từng thấy.
- Các chỉ số đánh giá có thể bao gồm độ chính xác, độ nhạy, độ đặc hiệu, AUC (Diện tích dưới đường cong ROC), và các chỉ số khác tùy thuộc vào bài toán cụ thể. Việc sử dụng các hàm và gói phân tích đánh giá trong R giúp người dùng dễ dàng đánh giá và tinh chỉnh mô hình của mình.
Quá trình huấn luyện và đánh giá mạng Bayesian đòi hỏi sự lặp đi lặp lại và tinh chỉnh, sử dụng cả kiến thức chuyên môn và phân tích dữ liệu, để đạt được mô hình tối ưu với khả năng dự đoán cao và độ chính xác tốt.
Ứng dụng thực tế Mạng Bayesian trong R
Một ứng dụng thực tế phổ biến của mạng Bayesian trong R là trong lĩnh vực y tế, ví dụ như dự đoán nguy cơ mắc bệnh dựa trên các yếu tố rủi ro. Giả sử chúng ta muốn xây dựng một mạng Bayesian để dự đoán nguy cơ mắc bệnh tim dựa trên các yếu tố như huyết áp, cholesterol, và lối sống.
Bước 1: Xác định Mạng và Các Biến
- Nút “Bệnh tim” (có/không) phụ thuộc vào ba nút khác: “Huyết áp” (cao/thấp), “Cholesterol” (cao/thấp), và “Lối sống” (khỏe mạnh/không khỏe mạnh).
Bước 2: Xác định và Nhập CPD
- Sử dụng dữ liệu lịch sử hoặc nghiên cứu để xác định CPD cho mỗi nút, ví dụ: xác suất mắc bệnh tim cao hơn ở những người có huyết áp cao và cholesterol cao.
Bước 3: Xây Dựng và Huấn Luyện Mô Hình
- Sử dụng gói
bnlearntrong R để xây dựng mạng:
library(bnlearn)
bn.model <- model2network("[Lối sống][Huyết áp|Lối sống][Cholesterol|Lối sống][Bệnh tim|Huyết áp:Cholesterol]")
cpd.list <- list()
cpd.list$`Lối sống` <- matrix(c(0.7, 0.3), ncol = 2, dimnames = list(NULL, c("Khỏe mạnh", "Không khỏe mạnh")))
# Định nghĩa tương tự cho các CPD khác...
fitted.bn <- custom.fit(bn.model, cpd.list)Bước 4: Dự Đoán và Phân Tích Kết Quả
- Sử dụng mô hình để dự đoán nguy cơ mắc bệnh tim dựa trên các thông tin cụ thể về bệnh nhân. Phân tích kết quả dự đoán để xác định mức độ rủi ro và khuyến nghị hành động phù hợp.
predict(fitted.bn, node = "Bệnh tim", evidence = list("Huyết áp" = "Cao", "Cholesterol" = "Cao", "Lối sống" = "Không khỏe mạnh"))Phân Tích Kết Quả:
- Giả sử mô hình dự đoán rằng một người có huyết áp cao, cholesterol cao và lối sống không khỏe mạnh có nguy cơ cao mắc bệnh tim. Kết quả này có thể giúp các bác sĩ đưa ra khuyến nghị về việc thay đổi lối sống hoặc can thiệp y tế để giảm nguy cơ.
Qua ví dụ này, mạng Bayesian chứng minh khả năng mạnh mẽ trong việc mô hình hóa sự phức tạp và không chắc chắn của các mối quan hệ giữa các biến, cung cấp thông tin quý giá cho quyết định y tế và can thiệp sức khỏe.

