
Phân cụm, hay clustering, là một kỹ thuật quan trọng trong khoa học dữ liệu, cho phép phân loại các đối tượng trong một tập dữ liệu thành các nhóm (cụm) dựa trên sự tương đồng của chúng. Mục tiêu của phân cụm là để các đối tượng trong cùng một nhóm có mức độ giống nhau cao, trong khi các đối tượng ở các nhóm khác nhau thì có sự khác biệt rõ ràng. Kỹ thuật này có ứng dụng rộng rãi trong nhiều lĩnh vực như marketing, sinh học, thư viện số, và phân tích mạng xã hội, giúp tiết lộ cấu trúc tự nhiên của dữ liệu, phát hiện mẫu và hỗ trợ ra quyết định.
Phân cụm dựa trên mật độ, một phương pháp tiếp cận đặc biệt trong clustering, tập trung vào việc xác định các cụm dựa trên mật độ của các điểm dữ liệu. Khác biệt so với các phương pháp phân cụm truyền thống như k-means, phân cụm dựa trên mật độ không yêu cầu xác định số lượng cụm trước và có thể xử lý tốt với dữ liệu có hình dạng phức tạp hoặc nhiễu. Phương pháp này sử dụng mật độ của điểm dữ liệu để xác định các cụm, với ý tưởng rằng một cụm được hình thành từ các điểm dữ liệu gần gũi về không gian, tạo thành một khu vực có mật độ dữ liệu cao, ngược lại với các khu vực có mật độ thấp hoặc nhiễu.
Phương pháp này có một số lợi thế đáng chú ý như khả năng phát hiện cụm có hình dạng bất kỳ và khả năng xử lý nhiễu trong dữ liệu. Tuy nhiên, nó cũng đòi hỏi việc lựa chọn cẩn thận các tham số như bán kính mật độ và số lượng tối thiểu các điểm, điều này có thể ảnh hưởng đến kết quả phân cụm. Sự khác biệt cơ bản với các phương pháp khác làm cho phân cụm dựa trên mật độ trở thành công cụ mạnh mẽ trong việc khám phá dữ liệu phức tạp, cung cấp cái nhìn sâu sắc về cấu trúc tự nhiên và động lực của dữ liệu.
Clustering Density-based – background
Trong bối cảnh của phân cụm dựa trên mật độ, “mật độ” được định nghĩa là số lượng điểm dữ liệu trong một khu vực nhất định của không gian dữ liệu. Mật độ cao ám chỉ một tập hợp lớn các điểm dữ liệu gần gũi với nhau, tạo thành cơ sở để phát hiện cụm trong phương pháp phân cụm này. Phương pháp này dựa trên nguyên tắc rằng các điểm thuộc về cùng một cụm sẽ tập trung gần nhau tạo thành một khu vực có mật độ cao, trong khi các khu vực có mật độ thấp hơn phân chia các cụm này ra khỏi nhau.
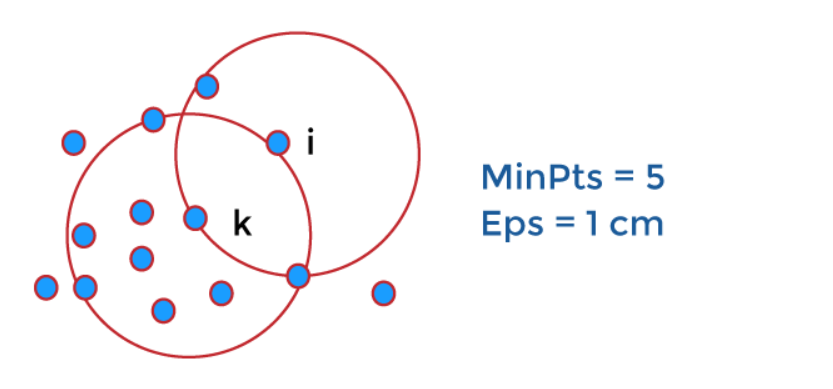
Có ba loại điểm dữ liệu quan trọng trong phân cụm dựa trên mật độ:
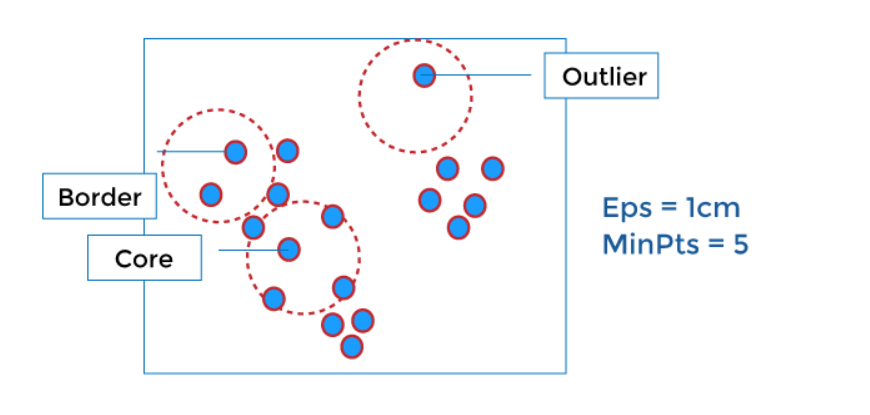
- Điểm Lõi (Core Points): Điểm lõi là điểm có số lượng điểm dữ liệu trong phạm vi lân cận nhất định (được xác định bởi bán kính EPS) đạt hoặc vượt qua một ngưỡng nhất định (MinPts). Điểm này thể hiện một khu vực có mật độ dữ liệu cao và là điểm khởi đầu để hình thành một cụm.
- Điểm Biên (Border Points): Điểm biên là điểm không đủ điều kiện là điểm lõi nhưng nằm trong khu vực lân cận của một hoặc nhiều điểm lõi. Dù không tạo ra mật độ nhưng điểm biên vẫn được coi là một phần của cụm do sự gần gũi với điểm lõi.
- Điểm Nhiễu (Noise Points): Điểm nhiễu là điểm không phải là điểm lõi và cũng không nằm gần bất kỳ điểm lõi nào. Điểm này không thuộc về bất kỳ cụm nào và được coi là nhiễu hoặc dữ liệu ngoại lai.
Nguyên tắc hoạt động của phân cụm dựa trên mật độ bắt đầu bằng việc xác định tất cả các điểm lõi dựa trên các tham số EPS và MinPts đã chọn. Từ các điểm lõi này, thuật toán mở rộng cụm bằng cách bao gồm tất cả các điểm biên liên kết trực tiếp hoặc gián tiếp với điểm lõi, tạo thành các cụm dựa trên mật độ. Điểm nhiễu được xác định sau cùng và không được bao gồm vào bất kỳ cụm nào.
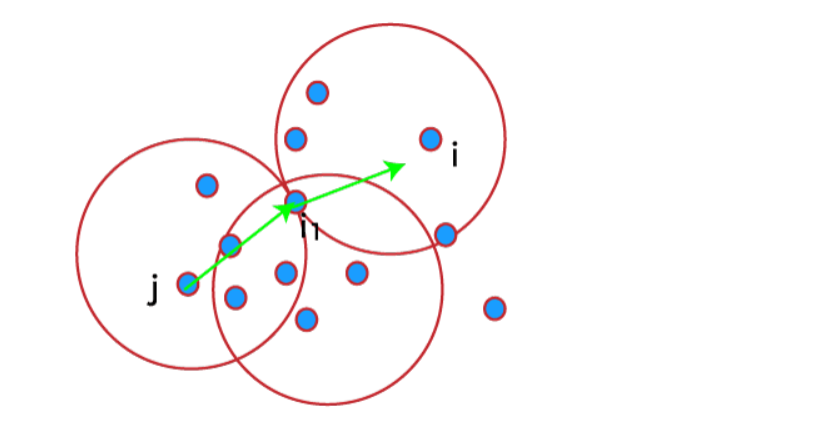
Phương pháp phân cụm dựa trên mật độ, như DBSCAN và OPTICS, hiệu quả trong việc xử lý dữ liệu có hình dạng phức tạp và nhiễu, cung cấp một cách linh hoạt và mạnh mẽ để phân tích và hiểu rõ cấu trúc tự nhiên của dữ liệu.
Phương pháp clustering Density-based
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Cách Thức Hoạt Động: DBSCAN là một trong những phương pháp phân cụm dựa trên mật độ phổ biến nhất. Thuật toán này xác định cụm dựa trên mật độ của điểm dữ liệu. Một điểm dữ liệu được coi là một phần của cụm nếu có đủ số lượng điểm lân cận (MinPts) trong phạm vi bán kính nhất định (EPS). DBSCAN bắt đầu từ một điểm ngẫu nhiên, tìm tất cả điểm lân cận theo tiêu chí mật độ và mở rộng cụm cho đến khi không còn điểm nào trong khu vực mật độ cao.
Ưu Điểm:
- Không yêu cầu xác định trước số lượng cụm.
- Có thể phát hiện các cụm với hình dạng phức tạp và cô lập điểm nhiễu.
- Hiệu quả với dữ liệu có mật độ không đồng nhất.
Nhược Điểm:
- Chọn tham số (EPS và MinPts) có thể khó khăn và ảnh hưởng lớn đến kết quả clustering.
- Kém hiệu quả với dữ liệu có mật độ biến đổi lớn.
OPTICS (Ordering Points To Identify the Clustering Structure)
Giới Thiệu và So Sánh với DBSCAN: OPTICS tương tự như DBSCAN nhưng cải thiện việc xử lý dữ liệu với mật độ biến đổi. Thay vì sử dụng một giá trị EPS cố định, OPTICS khám phá dữ liệu theo thứ tự tăng dần của mật độ, cho phép nó xác định cấu trúc cụm trong dữ liệu với mật độ biến đổi lớn. Điều này làm cho OPTICS linh hoạt hơn trong việc xác định số lượng và kích thước cụm.
Ưu Điểm so với DBSCAN:
- Khả năng xử lý tốt hơn với dữ liệu có mật độ biến đổi.
- Không cần thiết lập giá trị EPS cố định, làm giảm độ phức tạp của việc chọn tham số.
Nhược Điểm:
- Có thể mất nhiều thời gian và tài nguyên hơn DBSCAN do tính toán phức tạp hơn.
- Kết quả phụ thuộc vào giá trị của tham số MinPts.
DENCLUE
DENCLUE (Density-Based Clustering) là một thuật toán phân cụm dựa trên mật độ được thiết kế để xử lý dữ liệu đa chiều trong không gian lớn. Thuật toán này được giới thiệu bởi Hinneburg và Keim vào năm 1998. DENCLUE sử dụng các hàm mật độ xác suất để xác định cấu trúc cụm trong dữ liệu, khác biệt với DBSCAN và OPTICS về cách tiếp cận mật độ. Nó dựa trên nguyên tắc rằng cụm có thể được xác định qua các khu vực trong không gian dữ liệu có mật độ cao, được bao quanh bởi khu vực có mật độ thấp.
Cách Thức Hoạt Động:
- Xác định Hàm Mật Độ: DENCLUE sử dụng một hàm mật độ xác suất, thường là hàm Gaussian, để tính toán mật độ tại mỗi điểm trong không gian dữ liệu. Mật độ tại một điểm được tính bằng tổng đóng góp của mật độ từ tất cả các điểm khác trong dữ liệu.
- Tìm Điểm Hấp Dẫn: Thuật toán sau đó tìm các điểm hấp dẫn, là các điểm trong không gian dữ liệu nơi hàm mật độ đạt giá trị cực đại cục bộ. Các điểm này đại diện cho tâm của các cụm tiềm năng.
- Phân Cụm: Các điểm dữ liệu được gán vào cụm dựa trên sự thu hút của chúng với các điểm hấp dẫn. Nếu một điểm không được thu hút bởi bất kỳ điểm hấp dẫn nào, nó có thể được coi là nhiễu.
Ưu Điểm:
- Có khả năng xử lý dữ liệu có mật độ biến đổi và hình dạng cụm phức tạp.
- Phù hợp với dữ liệu đa chiều lớn.
- Khả năng xác định rõ ràng các cụm dựa trên lý thuyết xác suất.
Nhược Điểm:
- Tính toán có thể trở nên khá phức tạp và tốn kém với dữ liệu lớn do cần tính toán mật độ cho mỗi điểm dữ liệu.
- Việc chọn hàm mật độ và các tham số cần thiết (như bán kính của hàm Gaussian) có thể ảnh hưởng đến kết quả phân cụm và đôi khi không dễ dàng.
Ưu điểm và hạn chế của Clustering Density-based
Ưu điểm của Clustering Density-based:
- Xử lý dữ liệu có nhiễu: Clustering Density-based có khả năng xử lý dữ liệu chứa nhiễu tốt. Điều này là do phương pháp sử dụng mật độ dữ liệu để xác định các nhóm, do đó, nó có khả năng phát hiện và loại bỏ các điểm nhiễu.
- Khả năng phát hiện các cụm có hình dạng phức tạp: Clustering Density-based có khả năng phát hiện các cụm có hình dạng và kích thước không đều. Phương pháp này dựa trên mật độ dữ liệu để xác định các cụm, do đó, nó có thể xử lý các cụm có hình dạng phức tạp và kích thước khác nhau.
- Tự động xác định số lượng cụm: Clustering Density-based không yêu cầu người dùng xác định trước số lượng cụm cần tạo. Phương pháp này tự động xác định số lượng cụm dựa trên mật độ dữ liệu và các thông số định nghĩa.
Hạn chế của Clustering Density-based:
- Phụ thuộc vào tham số: Clustering Density-based có một số tham số quan trọng như khoảng cách tối thiểu và số lượng điểm tối thiểu trong mỗi cụm. Việc lựa chọn tham số phù hợp có thể ảnh hưởng đến kết quả clustering. Nếu không chọn tham số đúng, kết quả clustering có thể không chính xác.
- Nhạy cảm với sự biến đổi mật độ: Clustering Density-based có thể không hiệu quả khi xử lý dữ liệu có sự biến đổi mật độ lớn. Khi mật độ dữ liệu không đồng đều trong không gian, việc xác định các cụm có thể bị ảnh hưởng bởi sự biến đổi này.
- Hiệu suất tính toán: Clustering Density-based có thể yêu cầu tính toán phức tạp, đặc biệt đối với các tập dữ liệu lớn. Việc tính toán khoảng cách và mật độ dữ liệu có thể đòi hỏi nhiều tài nguyên tính toán và thời gian xử lý.
Lưu ý rằng các ưu điểm và hạn chế của Clustering Density-based có thể thay đổi tùy thuộc vào cài đặt cụ thể và đặc điểm của tập dữ liệu.

