
Machine Learning (ML), một nhánh của trí tuệ nhân tạo (AI), đang thay đổi cách chúng ta tương tác với thế giới xung quanh. Định nghĩa một cách đơn giản, ML là quá trình mà trong đó máy tính học hỏi từ dữ liệu để đưa ra quyết định hoặc dự đoán mà không cần được lập trình cụ thể cho từng tình huống. Không giống như truyền thống lập trình, nơi các quy tắc được định nghĩa rõ ràng và cứng nhắc, ML cho phép máy tính ‘học’ và thích ứng với các tình huống mới thông qua phân tích dữ liệu.
Tầm quan trọng của dữ liệu trong ML không thể được nhấn mạnh đủ. Dữ liệu là nguồn nguyên liệu cơ bản để ‘nuôi dưỡng’ các mô hình ML. Chất lượng và lượng dữ liệu quyết định độ chính xác và hiệu quả của mô hình. Trong môi trường ML, dữ liệu thường được phân chia thành hai loại chính: Training Set và Testing Set.
- Training Set là cơ sở để xây dựng và ‘huấn luyện’ mô hình. Mô hình ML học từ dữ liệu này, tự mình phát hiện ra các mẫu và quy luật nằm trong dữ liệu. Càng nhiều và đa dạng dữ liệu trong Training Set, mô hình càng có khả năng học hỏi tốt hơn và trở nên thông minh hơn.
- Testing Set, mặt khác, được sử dụng để đánh giá mô hình. Sau khi ‘huấn luyện’ xong trên Training Set, mô hình được thử nghiệm trên Testing Set để kiểm tra xem nó có thể áp dụng những gì đã học vào dữ liệu mới mà nó chưa từng thấy trước đây hay không. Điều này giúp đánh giá khách quan về khả năng tổng quát hóa của mô hình.
Trong bài viết này, chúng ta sẽ khám phá sâu hơn về cách hai loại dữ liệu này tạo nên nền tảng cho quá trình học máy, và tại sao việc phân chia chúng một cách cẩn thận là quan trọng đối với sự thành công của bất kỳ dự án ML nào.
Khái niệm về Training Set
Training Set là trái tim của bất kỳ mô hình Machine Learning nào. Đây là tập hợp dữ liệu mà từ đó mô hình học cách đưa ra quyết định hoặc dự đoán. Khi nói đến Machine Learning, định nghĩa “học” có thể được hiểu là quá trình tìm hiểu và xác định các mẫu hoặc xu hướng từ dữ liệu. Training Set cung cấp nguồn dữ liệu cần thiết cho mô hình để “học” những điều này.
Vai trò của Training Set không thể bị xem nhẹ. Nó không chỉ cung cấp thông tin mà còn ảnh hưởng trực tiếp đến hiệu suất và độ chính xác của mô hình ML. Một Training Set lớn và đa dạng sẽ giúp mô hình phát triển khả năng tổng quát hóa tốt hơn, trong khi một tập dữ liệu hạn chế hoặc thiên vị có thể dẫn đến overfitting, nơi mô hình hoạt động tốt trên dữ liệu huấn luyện nhưng thất bại trong việc dự đoán hoặc phân loại dữ liệu mới.
Thu thập và chuẩn bị dữ liệu cho Training Set là một quá trình quan trọng. Dữ liệu có thể được thu thập từ nhiều nguồn khác nhau như cơ sở dữ liệu, file logs, hoặc thậm chí từ Internet. Quan trọng hơn, dữ liệu cần được làm sạch và tiền xử lý để loại bỏ nhiễu và các giá trị thiếu. Chuẩn hóa hoặc chuẩn hóa dữ liệu cũng là một bước quan trọng, giúp đảm bảo rằng mô hình không bị ảnh hưởng bởi biến thiên trong quy mô của các tính năng.
Một ví dụ minh họa cách sử dụng Training Set có thể là quá trình xây dựng một mô hình để nhận diện hình ảnh. Trong trường hợp này, Training Set bao gồm hàng ngàn ảnh cùng với nhãn của chúng (ví dụ: ảnh của mèo được nhãn là “mèo”). Mô hình được ‘huấn luyện’ bằng cách sử dụng tập hợp này để học cách phân biệt hình ảnh của mèo so với những hình ảnh khác. Qua trình huấn luyện, mô hình học được các đặc điểm riêng biệt của mèo, như hình dạng của tai, mắt, và bộ lông, giúp nó có khả năng nhận diện mèo trong các hình ảnh mới mà nó chưa từng thấy.
Khái niệm về Testing Set
Testing Set đóng một vai trò quan trọng trong việc đánh giá và đảm bảo chất lượng của mô hình Machine Learning. Khác với Training Set, mà ở đó mô hình ‘học’ và phát triển khả năng của mình, Testing Set là tập hợp dữ liệu được sử dụng để kiểm tra và đánh giá hiệu suất của mô hình sau quá trình huấn luyện. Điều này giúp xác định xem mô hình có khả năng tổng quát hóa đối với dữ liệu mới, không thấy trong quá trình huấn luyện, hay không.
Vai trò chính của Testing Set là cung cấp một phương tiện đánh giá khách quan cho mô hình ML. Mô hình được huấn luyện trên Training Set, nhưng đánh giá của nó phải dựa trên dữ liệu mà nó chưa từng ‘nhìn thấy’ trước đó. Điều này giúp đảm bảo rằng mô hình không chỉ hoạt động tốt với dữ liệu huấn luyện mà còn có khả năng ứng dụng vào thực tế, với các tình huống và dữ liệu mới.
Sự khác biệt cơ bản giữa Testing Set và Training Set nằm ở việc sử dụng chúng. Training Set giúp mô hình ‘học’, trong khi Testing Set kiểm tra xem mô hình đã ‘học’ được bao nhiêu. Một phân chia rõ ràng giữa hai loại dữ liệu này giúp ngăn chặn vấn đề overfitting, nơi mô hình hoạt động tốt với dữ liệu huấn luyện nhưng không hiệu quả với dữ liệu mới.
Ví dụ minh họa cách sử dụng Testing Set có thể là trong việc phát triển một mô hình dự đoán thời tiết. Mô hình này có thể được ‘huấn luyện’ sử dụng lịch sử dữ liệu thời tiết (Training Set) để học cách dự đoán các điều kiện thời tiết. Sau đó, Testing Set, bao gồm một tập dữ liệu thời tiết khác không được sử dụng trong quá trình huấn luyện, được dùng để đánh
giá mô hình. Nếu mô hình có thể chính xác dự đoán thời tiết dựa trên Testing Set, điều này cho thấy nó đã học được cách tổng quát hóa từ dữ liệu huấn luyện và có thể áp dụng vào dữ liệu thực tế mà nó chưa từng gặp trước đây.
Tầm quan trọng của việc phân chia dữ liệu
Phân chia dữ liệu thành Training Set và Testing Set là một bước không thể thiếu trong quá trình phát triển một mô hình Machine Learning. Việc này không chỉ quan trọng mà còn cần thiết để xây dựng một mô hình ML chính xác và hiệu quả. Lý do chính đằng sau việc phân chia dữ liệu là để kiểm soát và ngăn chặn hiện tượng overfitting – khi mô hình quá khớp với dữ liệu huấn luyện và không hoạt động tốt trên dữ liệu mới.
- Phân chia dữ liệu giúp đánh giá khách quan về hiệu suất mô hình. Sử dụng Testing Set riêng biệt, chưa từng được “nhìn thấy” bởi mô hình trong quá trình huấn luyện, cho phép đánh giá mức độ hiệu quả mô hình áp dụng những gì đã học vào thực tế.
- Nó cũng giúp xác định khả năng tổng quát hóa của mô hình. Một mô hình tốt không chỉ hoạt động tốt trên dữ liệu mà nó đã được huấn luyện (Training Set) mà còn cần phải dự đoán chính xác trên dữ liệu mới (Testing Set).
Có nhiều phương pháp phân chia dữ liệu, mỗi phương pháp có ưu và nhược điểm riêng:
- Split Randomly (Phân chia ngẫu nhiên): Đây là phương pháp đơn giản nhất, nơi dữ liệu được phân chia một cách ngẫu nhiên thành Training Set và Testing Set, thường theo tỷ lệ nhất định như 70/30 hoặc 80/20. Phương pháp này đảm bảo rằng mỗi mẫu dữ liệu có cơ hội ngang nhau để được chọn vào một trong hai tập.
- Stratified Split (Phân chia theo tầng): Trong phương pháp này, dữ liệu được phân chia dựa trên một đặc tính cụ thể, đảm bảo rằng cả Training Set và Testing Set đều có phân bổ đại diện đều đặn từ mỗi tầng của đặc tính đó. Ví dụ, trong tác vụ phân loại, stratified split đảm bảo rằng tỷ lệ các lớp trong cả hai tập là tương tự nhau.
- Time-Based Split (Phân chia theo thời gian): Đối với dữ liệu có yếu tố thời gian, chẳng hạn như chuỗi thời gian ho
ặc dữ liệu giao dịch, phương pháp này phân chia dữ liệu dựa trên thời gian. Ví dụ, dữ liệu từ năm đầu tiên có thể được sử dụng làm Training Set, trong khi dữ liệu từ năm tiếp theo được sử dụng làm Testing Set. Điều này giúp mô hình học cách dự đoán tương lai dựa trên xu hướng quá khứ.
- Cross-Validation (Kiểm định chéo): Dù không phải là một phương pháp phân chia cố định, nhưng kiểm định chéo là một kỹ thuật quan trọng giúp đánh giá hiệu suất mô hình. Trong kiểm định chéo, dữ liệu được chia thành nhiều “fold” và mỗi fold lần lượt được sử dụng làm Testing Set, trong khi các fold còn lại được sử dụng làm Training Set. Điều này giúp đánh giá hiệu suất mô hình một cách toàn diện hơn.
Quá trình phân chia dữ liệu là cân nhắc cẩn thận giữa nhu cầu của mô hình và tính chất của dữ liệu. Không có phương pháp “một kích cỡ phù hợp với tất cả”; lựa chọn phương pháp phù hợp phụ thuộc vào mục tiêu cụ thể của dự án, tính chất của dữ liệu và yêu cầu về hiệu suất mô hình.
Vấn đề Overfitting và Underfitting
Trong thế giới của Machine Learning, hai vấn đề thường gặp là overfitting và underfitting. Cả hai đều có ảnh hưởng lớn đến hiệu suất của mô hình, nhưng lại mô tả hai kịch bản hoàn toàn khác nhau.
Overfitting xảy ra khi một mô hình Machine Learning quá khớp với dữ liệu huấn luyện. Nói cách khác, mô hình học từ dữ liệu huấn luyện đến mức nó không chỉ nắm bắt các mẫu và xu hướng chính, mà còn bao gồm cả nhiễu và các chi tiết không liên quan. Kết quả là, mặc dù mô hình này có thể hoạt động tốt với dữ liệu huấn luyện, nó thường không thể tổng quát hóa hiệu quả trên dữ liệu mới. Điều này làm giảm khả năng áp dụng mô hình trong thực tế, nơi dữ liệu mới và không dự đoán trước được liên tục xuất hiện.
Underfitting, ngược lại, xảy ra khi mô hình không học đủ từ dữ liệu huấn luyện. Điều này thường xuất hiện khi mô hình quá đơn giản so với độ phức tạp của dữ liệu, hoặc khi không có đủ dữ liệu để mô hình có thể học một cách hiệu quả. Mô hình underfitting thường không nắm bắt được các mẫu cơ bản trong dữ liệu và do đó, không thể dự đoán chính xác cả trên dữ liệu huấn luyện lẫn dữ liệu kiểm thử.
Vai trò của Training Set và Testing Set trong việc nhận biết và khắc phục những vấn đề này là cực kỳ quan trọng.
- Đối với Overfitting: Testing Set cung cấp một bức tranh rõ ràng về hiệu suất mô hình trên dữ liệu mới. Nếu một mô hình có hiệu suất cao trên Training Set nhưng lại thấp trên Testing Set, đây là dấu hiệu cảnh báo về overfitting. Để khắc phục, có thể áp dụng các kỹ thuật như làm đơn giản mô hình, sử dụng kỹ thuật regularization, hoặc cung cấp thêm dữ liệu huấn luyện đa dạng.
- Đối với Underfitting: Một mô hình có hiệu suất kém cả trên Training Set và Testing Set có khả năng đang gặp phải vấn đề underfitting. Điều này có thể được giải quyết bằng cách tăng độ phức tạp của mô
hình, chẳng hạn như thêm nhiều lớp hoặc nơ-ron trong mạng neural, hoặc bằng cách tinh chỉnh các tham số huấn luyện. Thêm vào đó, đôi khi việc tăng lượng dữ liệu huấn luyện hoặc cải thiện chất lượng dữ liệu cũng có thể giúp giải quyết vấn đề underfitting.
Sử dụng các kỹ thuật kiểm định chéo (cross-validation) cũng là một cách hiệu quả để nhận diện sớm cả hai vấn đề này. Kiểm định chéo không chỉ cung cấp một đánh giá toàn diện về hiệu suất mô hình trên nhiều tập dữ liệu khác nhau mà còn giúp xác định xem mô hình có thực sự hiệu quả hay không.
Data Trainning và Test trong Python
Khi chúng tôi làm việc với tập dữ liệu, một thuật toán học máy hoạt động theo hai giai đoạn. Chúng tôi thường chia nhỏ dữ liệu khoảng 20% -80% giữa các giai đoạn thử nghiệm và đào tạo. Trong quá trình học có giám sát, chúng tôi chia tập dữ liệu thành dữ liệu đào tạo và dữ liệu thử nghiệm trong Python ML.

Một. Điều kiện tiên quyết cho dữ liệu huấn luyện và thử nghiệm
Chúng ta sẽ cần các thư viện Python sau cho hướng dẫn này – pandas và sklearn.
Chúng tôi có thể cài đặt những thứ này bằng pip-
pip install pandas pip install sklearn
Chúng tôi sử dụng gấu trúc để nhập tập dữ liệu và sklearn để thực hiện phân tách. Bạn có thể nhập các gói này dưới dạng-
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris
Bạn có biết về các định dạng tệp dữ liệu Python – Cách đọc CSV, JSON, XLS
Xem thêm 11 phần mềm machine learning hàng đầu
Làm thế nào để Tách Tập huấn luyện và Thử nghiệm trong Học máy Python?
Sau đây là quy trình Tập huấn và Kiểm tra trong Python ML. Vì vậy, trước tiên hãy lấy một tập dữ liệu.

Tải tập dữ liệu
Hãy tải tập dữ liệu cháy rừng bằng cách sử dụng pandas.
data=pd.read_csv('forestfires.csv')
data.head()
Chia tách
Hãy chia dữ liệu này thành các nhãn và tính năng. Bây giờ, đó là gì? Sử dụng các tính năng, chúng tôi dự đoán nhãn. Ý tôi là sử dụng các tính năng (dữ liệu chúng tôi sử dụng để dự đoán nhãn), chúng tôi dự đoán nhãn (dữ liệu chúng tôi muốn dự đoán).
y=data.temp
x=data.drop('temp',axis=1)Temp là một nhãn để dự đoán nhiệt độ theo y; chúng ta sử dụng hàm drop () để lấy tất cả các dữ liệu khác trong x. Sau đó, chúng tôi chia nhỏ dữ liệu.
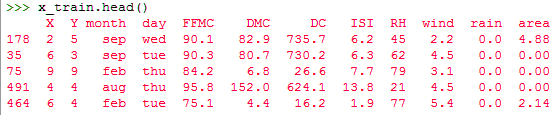
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2) x_train.head()
x_train.shape
Bạn có biết cách làm việc với cơ sở dữ liệu quan hệ bằng Python không
x_test.head()

Dòng test_size = 0,2 gợi ý rằng dữ liệu kiểm tra phải là 20% của tập dữ liệu và phần còn lại phải là dữ liệu huấn luyện. Với kết quả đầu ra của các hàm shape (), bạn có thể thấy rằng chúng ta có 104 hàng trong dữ liệu thử nghiệm và 413 hàng trong dữ liệu huấn luyện.
Xem thêm Các ứng dụng của Machine Learning trong thực tế
Một ví dụ khác
Hãy lấy một ví dụ khác. Chúng tôi sẽ sử dụng bộ dữ liệu IRIS lần này.
iris=load_iris() x,y=iris.data,iris.target x_train,x_test,y_train,y_test=train_test_split(x,y, train_size=0.5, test_size=0.5, random_state=123) y_test y_train
Hãy khám phá Thiết lập môi trường học máy Python
Vẽ sơ đồ của Train và Test Set bằng Python
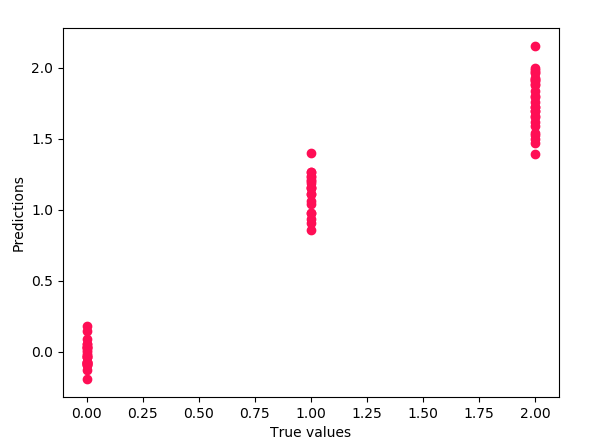
Chúng tôi phù hợp với mô hình của mình trên dữ liệu tàu để đưa ra dự đoán về nó. Hãy nhập mô hình tuyến tính từ sklearn, áp dụng hồi quy tuyến tính cho tập dữ liệu và vẽ biểu đồ kết quả.
from sklearn.linear_model import LinearRegression as lm model=lm().fit(x_train,y_train) predictions=model.predict(x_test) import matplotlib.pyplot as plt plt.scatter(y_test,predictions)
plt.xlabel('True values')plt.ylabel('Predictions')plt.show()
Vì vậy, đây là tất cả về Tập huấn luyện và thử nghiệm trong Học máy Python. Hy vọng bạn thích giải thích của chúng tôi.
Validation Set – Bước tiếp theo sau Training và Testing
Trong quá trình phát triển mô hình Machine Learning, một thành phần quan trọng khác cần được xem xét là Validation Set. Validation Set đóng vai trò cầu nối giữa quá trình huấn luyện (sử dụng Training Set) và kiểm thử (sử dụng Testing Set), giúp tối ưu hóa và hiệu chỉnh mô hình trước khi đánh giá cuối cùng.
Validation Set được sử dụng để điều chỉnh các tham số của mô hình (như hyperparameters) mà không làm tăng nguy cơ overfitting trên Testing Set.** Trong khi Training Set giúp xây dựng và “học” mô hình, và Testing Set dùng để kiểm tra hiệu suất cuối cùng, Validation Set cung cấp một tập dữ liệu riêng biệt để kiểm tra và điều chỉnh mô hình trong quá trình phát triển. Điều này cho phép các nhà phát triển và nhà khoa học dữ liệu đánh giá hiệu suất và tối ưu hóa mô hình mà không làm ảnh hưởng đến tính khách quan của Testing Set.
Sự khác biệt giữa Validation Set và Testing Set nằm ở cách sử dụng của chúng. Validation Set thường được sử dụng nhiều lần trong quá trình phát triển mô hình để điều chỉnh các hyperparameters và kiểm tra các thay đổi. Trái lại, Testing Set chỉ nên được sử dụng một lần sau khi tất cả các điều chỉnh đã hoàn tất để đánh giá hiệu suất cuối cùng của mô hình. Việc sử dụng Testing Set nhiều lần có thể dẫn đến việc mô hình “học” từ Testing Set, tạo ra nguy cơ overfitting.
Khi nào và làm thế nào sử dụng Validation Set? Validation Set thường được sử dụng sau khi mô hình đã được huấn luyện sơ bộ trên Training Set. Một phương pháp phổ biến là phân chia dữ liệu ban đầu thành ba phần: Training Set (ví dụ 70% dữ liệu), Validation Set (ví dụ 15% dữ liệu) và Testing Set (15% còn lại). Trong quá trình huấn luyện, Validation Set được sử dụng để đánh giá hiệu suất và điều chỉnh mô hình. Khi mô hình đã được tối ưu, Testing Set được sử dụng để kiểm tra hiệu suất cuối cùng.
Ngoài ra, kỹ thuật kiểm định chéo (cross-validation) có thể được sử dụng để tăng cường tính chính xác và độ tin cậy của quá trình tối ưu hóa mô hình, nhất là trong trường hợp dữ liệu hạn chế.
Kết luận
Hôm nay, chúng ta đã học cách chia CSV hoặc tập dữ liệu thành hai tập con – tập huấn luyện và tập kiểm tra trong Python Machine Learning. Chúng tôi thường để tập kiểm tra là 20% của toàn bộ tập dữ liệu và 80% còn lại sẽ là tập huấn luyện. Hơn nữa, nếu bạn có thắc mắc, hãy hỏi trong hộp nhận xét.

