
Multi-layer Perceptron (MLP), một phát triển đáng kể từ mô hình perceptron đơn giản ban đầu, là một cột mốc quan trọng trong lịch sử của mạng nơ-ron nhân tạo và học sâu. MLP được thiết kế để giải quyết các hạn chế của Single Layer Perceptron, đặc biệt là khả năng chỉ giải quyết được các bài toán phân loại tuyến tính. Với sự ra đời của MLP, người ta bắt đầu có khả năng mô phỏng các quá trình học phức tạp hơn, bao gồm cả những mô hình phi tuyến.
Cấu trúc cơ bản của MLP bao gồm ba loại lớp chính: lớp đầu vào (input layer), một hoặc nhiều lớp ẩn (hidden layers), và lớp đầu ra (output layer). Sự phối hợp giữa các lớp ẩn cho phép MLP học được từ dữ liệu đầu vào và thực hiện các dự đoán hoặc phân loại một cách chính xác hơn.
Mục đích chính của bài viết này là cung cấp một hướng dẫn chi tiết về cách xây dựng và sử dụng MLP trong môi trường TensorFlow, một trong những thư viện học máy và học sâu phổ biến nhất hiện nay. TensorFlow cung cấp các công cụ và API mạnh mẽ, giúp việc xây dựng, huấn luyện và triển khai các mô hình học sâu trở nên dễ dàng và hiệu quả. Qua bài viết, bạn sẽ học được cách tạo mô hình MLP từ cơ bản đến nâng cao, cách cấu hình các lớp ẩn, chọn hàm kích hoạt, và các bước để huấn luyện mô hình trên dữ liệu thực tế.
Bài viết không chỉ dừng lại ở việc cung cấp kiến thức kỹ thuật mà còn mở ra cánh cửa cho những ứng dụng thực tiễn của MLP trong nhiều lĩnh vực khác nhau, từ phân loại hình ảnh, dự đoán xu hướng, đến xử lý ngôn ngữ tự nhiên, giúp bạn đọc hiểu rõ hơn về sức mạnh và tiềm năng của mô hình này trong thế giới học máy ngày nay.
Định nghĩa Multi-layer Perceptron
Multi-layer Perceptron (MLP) là một kiểu mạng nơ-ron nhân tạo phức tạp, thuộc loại mạng nơ-ron tiến hóa (feedforward neural networks). Điểm nổi bật của MLP so với perceptron đơn giản là sự có mặt của một hoặc nhiều “lớp ẩn” (hidden layers) giữa lớp đầu vào (input layer) và lớp đầu ra (output layer). Mỗi lớp trong MLP bao gồm một số lượng nơ-ron, và mỗi nơ-ron thường được kết nối với tất cả nơ-ron ở lớp trước và sau nó.
Một đặc điểm quan trọng của MLP là khả năng của nó trong việc học các mối quan hệ phi tuyến tính. Điều này được thực hiện qua việc sử dụng các hàm kích hoạt phi tuyến (như ReLU, Sigmoid, hoặc Tanh) trong các nơ-ron của lớp ẩn. Các nơ-ron trong các lớp ẩn thực hiện các phép tính tổng trọng số của đầu vào từ lớp trước, sau đó áp dụng hàm kích hoạt để đưa ra đầu ra của nó.
Multi-layer Perceptron xác định kiến trúc phức tạp nhất của mạng nơ-ron nhân tạo. Về cơ bản, nó được hình thành từ nhiều lớp của perceptron. TensorFlow là một khung công tác học tập sâu rất phổ biến được phát hành và sổ tay này sẽ hướng dẫn xây dựng mạng nơ-ron với thư viện này. Nếu chúng ta muốn hiểu perceptron nhiều lớp là gì, chúng ta phải phát triển perceptron nhiều lớp từ đầu bằng cách sử dụng Numpy.
Biểu diễn bằng hình ảnh của việc học perceptron nhiều lớp như được hiển thị bên dưới-
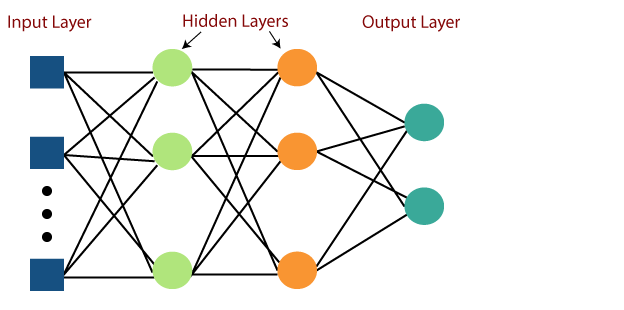
Mạng MLP được sử dụng cho định dạng học tập có giám sát. Một thuật toán học điển hình cho mạng MLP còn được gọi là thuật toán lan truyền ngược.
Multilayer perceptron (MLP) là một mạng nơ-ron nhân tạo chuyển tiếp các dữ liệu tạo ra từ một tập hợp các dữ liệu output từ một tập hợp các input.
MLP được đặc trưng với các lớp nút đầu vào có kết nối theo dạng đồ thị có hướng giữa các input node được kết nối dưới dạng đồ thị có hướng giữa input layer và output. MLP sử dụng backpropagation để trainning . MLP là một phương pháp Deep Learning.
MLP có khả năng giải quyết nhiều bài toán phức tạp mà perceptron đơn giản không thể, bao gồm phân loại và hồi quy cho dữ liệu phi tuyến. MLP đã trở thành nền tảng cơ bản cho nhiều phát triển sau này trong lĩnh vực học sâu, bao gồm mạng nơ-ron tích chập (CNN) và mạng nơ-ron hồi quy (RNN).
Cơ Sở Lý Thuyết về Multi-layer Perceptron (MLP)
Multi-layer Perceptron (MLP) là một loại mạng nơ-ron nhân tạo, phức tạp hơn so với Perceptron đơn giản, và được thiết kế để mô phỏng cách mà não bộ con người xử lý thông tin. Cấu trúc của MLP bao gồm ba loại lớp cơ bản:
- Input Layer:
- Lớp đầu vào này chứa nơ-ron đại diện cho các đặc trưng của dữ liệu đầu vào. Số lượng nơ-ron ở lớp này tương ứng với số lượng đặc trưng trong dữ liệu.
- Lớp này chủ yếu phục vụ như một điểm phân phối dữ liệu tới các lớp tiếp theo mà không thực hiện bất kỳ tính toán nào đáng kể.
- Hidden Layers:
- MLP thường có một hoặc nhiều lớp ẩn giữa lớp đầu vào và lớp đầu ra. Các lớp ẩn này là nơi xảy ra phần lớn các phép tính của mạng.
- Mỗi nơ-ron trong các lớp ẩn này thực hiện tổng trọng số của đầu vào từ lớp trước, sau đó áp dụng một hàm kích hoạt (ví dụ: ReLU, Sigmoid, hoặc Tanh) để đưa ra đầu ra của nó.
- Output Layer:
- Lớp đầu ra chứa nơ-ron cung cấp kết quả cuối cùng của mạng. Số lượng và loại của nơ-ron trong lớp này phụ thuộc vào bài toán cụ thể (ví dụ: phân loại, hồi quy, v.v.).
- Hàm kích hoạt của lớp đầu ra thường được chọn để phù hợp với bản chất của dữ liệu đầu ra (ví dụ: Softmax cho phân loại đa lớp).
Điểm Khác Biệt giữa MLP và Single Layer Perceptron
- Độ Phức Tạp:
- Single Layer Perceptron chỉ bao gồm một lớp và thích hợp với các bài toán phân loại tuyến tính đơn giản. Nó không có khả năng học các mối quan hệ phức tạp hoặc phi tuyến tính.
- MLP, với nhiều lớp ẩn, có khả năng xử lý dữ liệu phi tuyến và học được các mô hình phức tạp hơn nhiều.
- Tính Linh Hoạt và Ứng Dụng:
- Do hạn chế trong khả năng học, Single Layer Perceptron bị giới hạn trong việc giải quyết các bài toán phức tạp. Nó chủ yếu được sử dụng trong các tác vụ phân loại đơn giản và như một công cụ giáo dục.
- MLP có khả năng linh hoạt và thích ứng cao, có thể được áp dụng trong nhiều lĩnh vực khác nhau từ xử lý ngôn ngữ tự nhiên, nhận dạng hình ảnh, dự đoán dữ liệu tới hệ thống khuyến nghị.
Nhìn chung, MLP đánh dấu một bước tiến quan trọng trong việc phát triển các mô hình học máy, mở ra cánh cửa cho việc giải quyết nhiều vấn đề phức tạp hơn mà Single Layer Perceptron không thể xử lý.
Xây Dựng Multi-layer Perceptron (MLP) với TensorFlow
Bước 1: Khởi Tạo Mô Hình
Trước tiên, sử dụng Keras API trong TensorFlow để tạo một mô hình tuần tự (Sequential model). Mô hình tuần tự cho phép bạn xếp chồng các lớp lên nhau một cách trực quan và dễ dàng.
from tensorflow.keras.models import Sequential model = Sequential()
Bước 2: Thêm Các Lớp
Thêm các lớp vào mô hình, bao gồm lớp đầu vào, các lớp ẩn và lớp đầu ra. Sử dụng lớp Dense cho các lớp ẩn và lớp đầu ra. Dense là lớp fully-connected, nghĩa là mỗi nơ-ron trong một lớp được kết nối với tất cả nơ-ron ở lớp trước đó.
from tensorflow.keras.layers import Dense # Lớp đầu vào và lớp ẩn đầu tiên model.add(Dense(units=64, activation='relu', input_shape=(num_input_features,))) # Thêm một lớp ẩn model.add(Dense(units=32, activation='relu')) # Lớp đầu ra model.add(Dense(units=num_output_classes, activation='softmax'))
Trong đoạn mã này, num_input_features là số lượng đặc trưng của dữ liệu đầu vào, và num_output_classes là số lượng lớp hoặc giá trị đầu ra cho bài toán của bạn (ví dụ: 2 cho phân loại nhị phân, nhiều hơn cho phân loại đa lớp).
Bước 3: Biên Dịch Mô Hình
Sau khi xây dựng kiến trúc mô hình, bạn cần “biên dịch” nó với một optimizer, hàm loss, và metrics để đánh giá.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ở đây, adam là một lựa chọn phổ biến cho optimizer, và categorical_crossentropy thường được sử dụng cho các bài toán phân loại đa lớp.
Giới Thiệu về Các Hàm và Lớp trong TensorFlow
- Sequential Model: Mô hình này cho phép bạn tạo một mô hình layer-by-layer một cách tuần tự. Nó phù hợp cho hầu hết các loại mạng nơ-ron.
- Dense Layer: Là lớp cơ bản trong Keras, nơi mỗi nơ-ron nhận đầu vào từ tất cả nơ-ron ở lớp trước đó.
unitschỉ số lượng nơ-ron, vàactivationxác định hàm kích hoạt sử dụng. - Compile Method: Phương thức này cấu hình mô hình cho quá trình học, với việc xác định optimizer, hàm loss, và metrics.
Ví dụ, chúng tôi đang tập trung vào việc triển khai với MLP cho vấn đề phân loại hình ảnh.
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256
# 1st layer num features
n_hidden_2 = 256 # 2nd layer num features
n_input = 784 # MNIST data input (img shape: 28*28) n_classes = 10
# MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# weights layer 1
h = tf.Variable(tf.random_normal([n_input, n_hidden_1])) # bias layer 1
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# layer 1 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# weights layer 2
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
# bias layer 2
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# layer 2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# weights output layer
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
# biar output layer
bias_output = tf.Variable(tf.random_normal([n_classes])) # output layer
output_layer = tf.matmul(layer_2, output) + bias_output
# cost function
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(output_layer, y))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(
learning_rate = learning_rate).minimize(cost)
# Plot settings
avg_set = []
epoch_set = []
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print
Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost)
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print
"Training phase finished"
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print
"Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels})
Dòng mã trên tạo ra đầu ra sau-
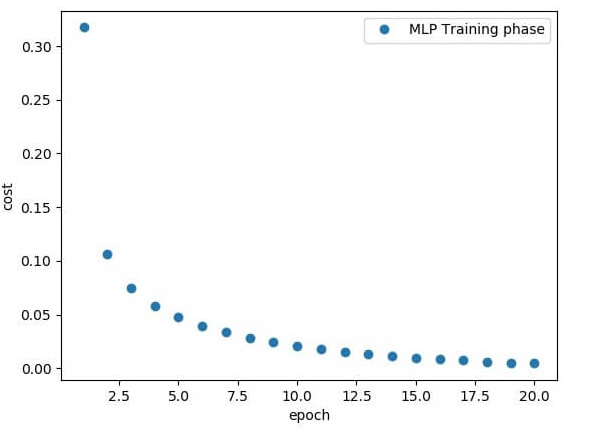
Thông qua những bước trên, bạn có thể xây dựng một mô hình MLP sử dụng TensorFlow, mở ra khả năng giải quyết nhiều bài toán phức tạp trong lĩnh vực học máy và học sâu.
Ứng Dụng của Multi-layer Perceptron (MLP) trong Thực Tiễn
Các Lĩnh Vực Ứng Dụng Chính
- Phân Loại Hình Ảnh:
- MLP được sử dụng rộng rãi trong việc phân loại hình ảnh, nơi nó học cách nhận dạng và phân biệt các đối tượng hoặc mẫu khác nhau trong ảnh. Ví dụ, ứng dụng trong nhận dạng khuôn mặt, phân loại loài động vật trong hình ảnh tự nhiên, hoặc phân biệt các loại xe cộ trong hình ảnh từ camera giám sát.
- Dự Đoán Chuỗi Thời Gian:
- Trong lĩnh vực tài chính, MLP có thể được sử dụng để dự đoán giá cổ phiếu hoặc tỷ giá hối đoái. Nó cũng được áp dụng trong dự báo thời tiết, nơi nó học từ dữ liệu lịch sử để dự đoán các xu hướng thời tiết trong tương lai.
- Xử Lý Ngôn Ngữ Tự Nhiên:
- MLP có thể được huấn luyện để thực hiện các tác vụ như phân loại văn bản (ví dụ: xác định tính cảm xúc trong đánh giá sản phẩm), phân loại email (spam hay không spam), và hơn thế nữa.
- Hệ Thống Gợi Ý:
- MLP được ứng dụng trong việc phát triển các hệ thống gợi ý, chẳng hạn như đề xuất sản phẩm trên các nền tảng thương mại điện tử hoặc đề xuất bài hát, phim trên các dịch vụ streaming.

