
Data Mining, hay khai thác dữ liệu, là quá trình phân tích và khám phá một lượng lớn dữ liệu để tìm ra các mẫu, xu hướng, và thông tin hữu ích, thường được sử dụng trong việc đưa ra quyết định kinh doanh, nghiên cứu khoa học, và nhiều ứng dụng khác. Phạm vi của Data Mining rất rộng, bao gồm nhưng không giới hạn ở phân tích cụm, phân loại, hồi quy, và phát hiện quy luật liên kết.
Trong quá trình khai thác, dữ liệu dư thừa và tương quan thường xuất hiện như những thách thức đáng kể. Dữ liệu dư thừa là sự lặp lại không cần thiết của dữ liệu hoặc tính năng, khiến cho việc xử lý dữ liệu trở nên nặng nề hơn và có thể làm giảm chất lượng của kết quả khai thác. Ví dụ, hai trường dữ liệu ghi lại cùng một thông tin nhưng dưới những tên khác nhau có thể được coi là dư thừa. Mặt khác, tương quan dữ liệu chỉ ra mối liên hệ giữa hai hoặc nhiều biến, có thể là tích cực (cùng tăng/giảm) hoặc tiêu cực (một tăng và một giảm). Việc hiểu rõ mối tương quan giữa các biến là quan trọng, vì nó có thể giúp loại bỏ các biến không cần thiết và giảm kích thước không gian dữ liệu, từ đó tối ưu hóa quá trình khai thác.
Xử lý dữ liệu dư thừa và tương quan trong Data Mining là cực kỳ quan trọng, vì nó không chỉ giúp giảm thiểu độ phức tạp và tăng hiệu suất tính toán, mà còn cải thiện độ chính xác và chất lượng của thông tin được khai thác. Bằng cách loại bỏ dữ liệu không cần thiết và tập trung vào các biến có ý nghĩa, các nhà phân tích có thể đạt được kết quả tốt hơn, nhanh chóng, và với chi phí thấp hơn. Do đó, việc nhận biết và xử lý hiệu quả các vấn đề về dư thừa và tương quan trở thành một phần không thể thiếu trong quy trình khai thác dữ liệu hiện đại.
Data Redundancy là gì?
Trong lĩnh vực Data Mining, dữ liệu dư thừa được định nghĩa là sự xuất hiện của dữ liệu hoặc thuộc tính không mang lại thông tin mới hoặc giá trị thêm vào tập dữ liệu. Dữ liệu dư thừa thường bao gồm các bản ghi lặp lại, các thuộc tính có giá trị giống hệt nhau hoặc các biến đại diện cho cùng một thông tin nhưng dưới các định dạng khác nhau.
Nguồn gốc của dữ liệu dư thừa có thể đến từ nhiều nguyên nhân khác nhau, bao gồm lỗi nhập liệu, quy trình tích hợp dữ liệu không đồng nhất từ nhiều nguồn, hoặc do thiết kế cơ sở dữ liệu không tối ưu. Ví dụ, trong một tập dữ liệu khách hàng, địa chỉ email và số điện thoại có thể được nhập nhiều lần cho cùng một người dùng do lỗi nhập liệu hoặc do người dùng đăng ký nhiều dịch vụ khác nhau.
Dữ liệu dư thừa có thể ảnh hưởng tiêu cực đến quá trình Data Mining bằng cách làm tăng độ phức tạp của dữ liệu, làm chậm quá trình xử lý và phân tích, và cuối cùng làm giảm chất lượng của kết quả khai thác. Dữ liệu dư thừa cũng có thể dẫn đến việc đưa ra các quyết định dựa trên thông tin không chính xác hoặc lệch lạc.
Để phát hiện và xử lý dữ liệu dư thừa, một số phương pháp và công cụ đã được phát triển. Các kỹ thuật pre-processing dữ liệu, như data cleaning và data normalization, giúp loại bỏ dữ liệu dư thừa và đồng nhất hóa dữ liệu. Công cụ như SQL queries, phần mềm quản lý dữ liệu, và các gói thư viện phân tích dữ liệu trong Python (như Pandas) cung cấp các chức năng mạnh mẽ để xác định và loại bỏ các bản ghi dư thừa hoặc các thuộc tính không cần thiết. Ngoài ra, các kỹ thuật nâng cao hơn như Principal Component Analysis (PCA) được sử dụng để giảm chiều dữ liệu và loại bỏ dữ liệu dư thừa trong quá trình dimensionality reduction, giúp cải thiện hiệu suất và độ chính xác của các mô hình Data Mining.
Hãy hiểu khái niệm này với sự trợ giúp của một ví dụ.
Giả sử chúng ta có một tập dữ liệu có ba thuộc tính – pizza_name, is_veg, is_nonveg
- Is_veg là 1; nếu pizza đang chọn là rau khác, nó là 0.
- Is_nonveg là 1; nếu pizza đang chọn không phải là bánh khác, nó là 0.
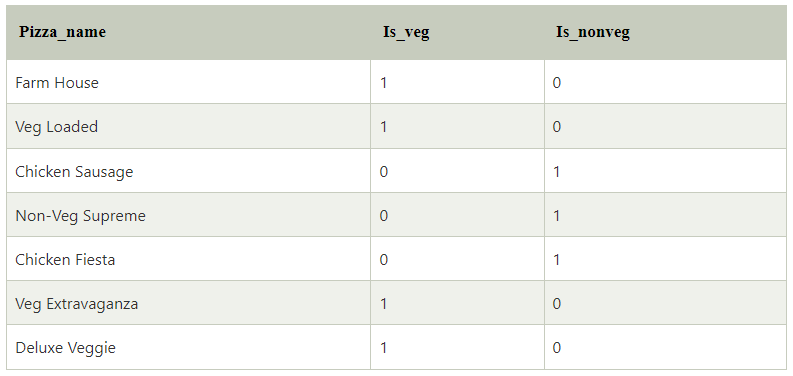
Khi phân tích bảng trên, chúng tôi nhận thấy rằng nếu một chiếc bánh pizza không phải là món ăn chay (tức là, is_veg là 0 khi chọn pizza_name), thì chiếc bánh đó chắc chắn không phải là món ăn chay (Vì chỉ có hai giá trị trong lớp đầu ra pizza_name- Veg và Nonveg ). Do đó, một trong những thuộc tính này trở nên thừa. Nó có nghĩa là hai thuộc tính có liên quan rất nhiều với nhau, và một thuộc tính có thể tìm thấy thuộc tính kia. Vì vậy, bạn có thể bỏ thuộc tính thứ nhất hoặc thứ hai mà không bị mất thông tin.
Correlation trong Data Mining
Tương quan trong Data Mining đề cập đến mối quan hệ giữa hai hoặc nhiều biến trong tập dữ liệu, cho biết mức độ và hướng mà một biến có thể dự đoán được từ biến khác. Tương quan có thể được phân loại thành ba loại chính: tương quan dương, tương quan âm và không tương quan.
Tương quan dương xảy ra khi giá trị của một biến tăng lên dẫn đến sự tăng lên của giá trị của biến kia; ví dụ, chiều cao và cân nặng của một người thường có mối tương quan dương, nghĩa là người cao thường nặng hơn. Ngược lại, tương quan âm là khi giá trị của một biến tăng lên nhưng giá trị của biến kia lại giảm xuống; một ví dụ điển hình là mối quan hệ giữa số lượng thuốc giảm cân tiêu thụ và trọng lượng cơ thể. Không tương quan tồn tại khi không có mối quan hệ rõ ràng nào giữa hai biến; ví dụ, màu sắc yêu thích của một người và thu nhập hàng năm của họ thường không có mối quan hệ tương quan.
Trong các tập dữ liệu khác nhau, tương quan dữ liệu có thể mang lại thông tin quan trọng. Ví dụ, trong tập dữ liệu bán hàng, có thể phát hiện ra mối tương quan giữa thời gian trong ngày và số lượng bán hàng, hoặc trong lĩnh vực y tế, có thể tìm thấy mối tương quan giữa việc tập thể dục và mức độ cholesterol.
Tương quan dữ liệu có ảnh hưởng đáng kể đến kết quả Data Mining bởi vì nó có thể giúp dự đoán giá trị của một biến dựa trên biến khác và cũng giúp xác định các biến quan trọng cần phải tập trung nghiên cứu. Tuy nhiên, một điểm quan trọng cần lưu ý là “tương quan không chứng minh nguyên nhân”; chỉ vì hai biến có mối tương quan không có nghĩa là một biến là nguyên nhân của biến kia.
Các phương pháp và công cụ để phân tích và xử lý tương quan dữ liệu bao gồm phân tích tương quan Pearson cho dữ liệu liên tục, phân tích tương quan Spearman cho dữ liệu thứ tự, và phân tích tương quan Kendall’s Tau. Công cụ như R, Python (với các thư viện như Pandas, NumPy, SciPy), và các phần mềm thống kê khác cung cấp các chức năng để tính toán hệ số tương quan và thực hiện các kiểm định thống kê để xác định mức độ đáng tin cậy của mối tương quan. Hiểu rõ và xử lý tương quan dữ liệu một cách chính xác là yếu tố quan trọng để đạt được kết quả Data Mining chính xác và có ý nghĩa.
Xử lý dữ liệu dư thừa và tương quan trong Data Mining
Xử lý dữ liệu dư thừa và tương quan trong Data Mining đòi hỏi một cách tiếp cận tổng thể, kết hợp các kỹ thuật từ giai đoạn pre-processing đến các phương pháp chọn lọc và giảm số lượng thuộc tính. Mục tiêu là tối ưu hóa tập dữ liệu cho quá trình khai thác, giúp cải thiện hiệu suất và độ chính xác của các mô hình được xây dựng.
Pre-processing và Data Cleaning
Giai đoạn đầu tiên trong việc xử lý dữ liệu là pre-processing và data cleaning, bao gồm việc loại bỏ dữ liệu dư thừa và sửa chữa hoặc loại bỏ dữ liệu nhiễu. Các kỹ thuật như loại bỏ các bản ghi trùng lặp, chuẩn hóa dữ liệu (đồng nhất hóa các định dạng dữ liệu), và xử lý các giá trị thiếu là những bước quan trọng. Việc này giúp đảm bảo rằng dữ liệu được đưa vào quá trình Data Mining là sạch sẽ, đáng tin cậy và phản ánh chính xác thông tin cần thiết.
Feature Selection và Dimensionality Reduction
Sau khi dữ liệu được làm sạch, việc chọn lọc và giảm số lượng thuộc tính (features) trở nên quan trọng. Feature selection là quá trình chọn ra những thuộc tính quan trọng nhất cho việc phân tích, loại bỏ những thuộc tính không mang lại nhiều thông tin hoặc có mối tương quan cao với nhau. Dimensionality reduction, như Principal Component Analysis (PCA) hoặc Linear Discriminant Analysis (LDA), giúp giảm số lượng thuộc tính bằng cách tạo ra một tập hợp các thuộc tính mới (components) từ sự kết hợp của các thuộc tính cũ, giữ lại phần lớn thông tin quan trọng.
Case Studies và Ví dụ Thực Tế
Trong thực tiễn, việc áp dụng các kỹ thuật xử lý dữ liệu dư thừa và tương quan đã được chứng minh là hiệu quả. Ví dụ, trong một dự án phân tích cảm xúc từ các bình luận trực tuyến, việc loại bỏ các từ dư thừa và sử dụng chỉ những từ quan trọng nhất (feature selection) đã giúp cải thiện độ chính xác của mô hình phân loại. Trong một nghiên cứu khác về dự đoán bệnh tim, việc áp dụng PCA để giảm số lượng biến từ dữ liệu lâm sàng và sinh học đã làm cho mô hình dự đoán trở nên hiệu quả hơn và dễ hiểu hơn.
Những ví dụ này minh họa sự cần thiết của việc xử lý cẩn thận dữ liệu dư thừa và tương quan trong Data Mining. Bằng cách làm sạch dữ liệu và chọn lọc thông tin một cách thông minh, các nhà khoa học dữ liệu có thể xây dựng những mô hình chính xác và hiệu quả hơn, đem lại giá trị thực sự từ dữ liệu lớn.
Thách thức, cơ hội và tương lai trong xử lý dữ liệu
Trong bối cảnh dữ liệu ngày càng lớn và phức tạp, việc xử lý dữ liệu dư thừa và tương quan đặt ra nhiều thách thức đồng thời mở ra cơ hội cho nghiên cứu và phát triển công cụ mới trong lĩnh vực Data Mining.
Một trong những thách thức lớn nhất là khả năng xử lý và phân tích dữ liệu ở quy mô lớn. Khi dữ liệu tăng lên về kích thước, việc xác định và loại bỏ dữ liệu dư thừa trở nên khó khăn hơn, đòi hỏi nhiều tài nguyên tính toán và thời gian hơn. Đối với dữ liệu tương quan, việc phát hiện và giải thích mối quan hệ giữa các biến trở nên phức tạp hơn, đặc biệt khi đối mặt với hiện tượng “curse of dimensionality”, nơi mà việc tăng số lượng thuộc tính (dimensions) làm giảm hiệu suất của mô hình. Ngoài ra, việc duy trì chất lượng và tính chính xác của dữ liệu trong quá trình làm sạch và chọn lọc thuộc tính cũng là một thách thức không nhỏ.
Mặt khác, những thách thức này cũng tạo ra cơ hội cho việc nghiên cứu và phát triển các công cụ và kỹ thuật mới. Có nhu cầu lớn cho các giải pháp tự động hóa có khả năng xử lý dữ liệu ở quy mô lớn một cách nhanh chóng và hiệu quả. Điều này bao gồm việc phát triển các thuật toán mới cho pre-processing dữ liệu, feature selection, và dimensionality reduction, cũng như sử dụng công nghệ mới như học sâu (deep learning) để phát hiện và xử lý dữ liệu dư thừa và tương quan. Ngoài ra, việc tận dụng dữ liệu không cấu trúc, như văn bản và hình ảnh, cũng mở ra cơ hội cho việc áp dụng các phương pháp mới trong việc khai thác thông tin và kiến thức từ dữ liệu phong phú và đa dạng này.
Tương lai của Data Mining trong bối cảnh dữ liệu ngày càng lớn và đa dạng hứa hẹn nhiều tiến bộ. Sự tiến bộ trong công nghệ lưu trữ và xử lý dữ liệu, cùng với sự phát triển của các thuật toán khai thác dữ liệu mới, sẽ cho phép các tổ chức và cá nhân khai thác sâu hơn vào dữ liệu để tìm ra thông tin hữu ích và kiến thức mới. Điều này không chỉ giúp cải thiện quyết định kinh doanh và nghiên cứu khoa học mà còn góp phần vào việc giải quyết các vấn đề xã hội thông qua việc phân tích và hiểu biết sâu sắc hơn về dữ liệu.

