TensorFlow Playground là một ứng dụng web được viết bằng d3.js (JavaScript). Và nó là ứng dụng tốt nhất để tìm hiểu về Mạng thần kinh (NN) mà không cần toán học. Trong trình duyệt web của chúng tôi, chúng tôi có thể tạo NN (Neural Network) và xem ngay kết quả của chúng tôi. Nó được cấp phép theo giấy phép Apache 2.0, tháng 1 năm 2004 (http://www.apache.org/licenses/).
Daniel Smilkov và Shan Carter tạo ra nó và dựa trên sự tiếp nối của nhiều tác phẩm trước đó. Và các thành viên đóng góp của nó là Fernanda Viegas và Martin Wattenberg và nhóm Big Picture và Google Brain để phản hồi và hướng dẫn.
Các bài viết liên quan:
TensorFlow Playground là một ứng dụng web cho phép người dùng kiểm tra thuật toán trí tuệ nhân tạo (AI) với thư viện máy học TensorFlow.
TensorFlow Playground không quen thuộc với các phép toán cấp cao và mã hóa với mạng nơ-ron để học sâu và các ứng dụng học máy khác. Các hoạt động của mạng nơ-ron tương tác và được biểu diễn trong Playground.
Thư viện mã nguồn mở được thiết kế cho các yêu cầu giáo dục.
Bây giờ hãy truy cập liên kết http://playground.tensorflow.org.

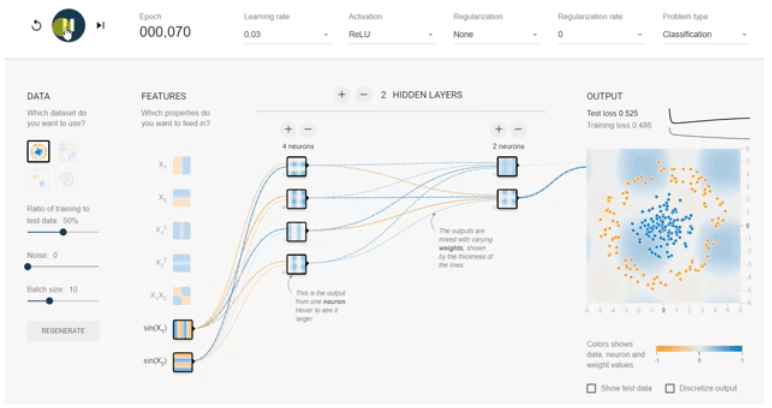
Phần trên cùng của trang web là Epoch, Learning rate, Activation, Regularization rate, Problem type, được mô tả bên dưới từng cái một.
Mỗi lần huấn luyện được tiến hành cho tập huấn luyện, và số Epoch tăng lên như chúng ta có thể thấy bên dưới.
Tỷ lệ học tập xác định tốc độ học tập; do đó, chúng ta cần lựa chọn tỷ lệ học tập phù hợp.

Chức năng kích hoạt của nút xác định đầu ra của nút đó hoặc tập dữ liệu. Mạch chip máy tính tiêu chuẩn có thể là một mạng kỹ thuật số có chức năng kích hoạt có thể là “ON” (1) hoặc “OFF” (0), tùy thuộc vào đầu vào của nó.

Soft Output Activation Function
ReLU (Rectified Linear Unit) g(y) = max(0,y)
Tanh (Hyperbolic Tangent) t(y) =

Sigmoid (logistic Sigmoid) σ(y) =

Linear (e.g., α=1) l(y)= αy

Việc điều tiết hóa được sử dụng để ngăn chặn tình trạng quá tải.
TensorFlow Playground thực hiện hai kiểu Regulization: L1, L2.
Việc điều tiết hóa có thể làm tăng hoặc giảm trọng lượng của một kết nối chắc chắn hoặc yếu để làm cho phân loại mẫu sắc nét hơn.
L1 và L2 là các phương pháp chính quy hóa phổ biến.

L1 Regularization
- L1 hữu ích trong không gian đặc trưng thưa thớt, nơi cần phải chọn một vài trong số rất nhiều.
- L1 sẽ thực hiện các lựa chọn và ấn định các giá trị trọng số quan trọng và sẽ làm cho trọng số của những giá trị không được chọn nhỏ nhất (hoặc bằng không)
L2 Regularization
- L2 có khả năng với các đầu vào tương quan
- L2 sẽ kiểm soát các giá trị trọng số trùng với mức độ tương quan.
Bỏ học cũng là một phương pháp chính quy hóa.
Tỷ lệ chính quy hóa cao hơn sẽ làm cho trọng lượng bị hạn chế hơn trong phạm vi.

Trong loại sự cố, hãy chọn trong số hai loại sự cố trong số bên dưới:
- Classification
- Regression

Chúng tôi phải xem loại vấn đề mà chúng tôi sẽ giải quyết dựa trên tập dữ liệu mà chúng tôi chỉ định ngay tại đây. Giải quyết dựa trên tập dữ liệu mà chúng tôi xác định bên dưới.

Nhìn chung, có bốn kiểu phân loại, và có hai dạng Bài toán hồi quy tồn tại được đưa ra dưới đây.

Ở đây, tập dữ liệu biểu mẫu chấm màu xanh lam và màu cam ngụ ý rằng
Chấm màu cam có giá trị -1. Giá trị chấm xanh là +1
Sử dụng Tỷ lệ huấn luyện của dữ liệu thử nghiệm, phần trăm của tập huấn luyện được kiểm soát bằng cách sử dụng mô-đun điều khiển ở đây.
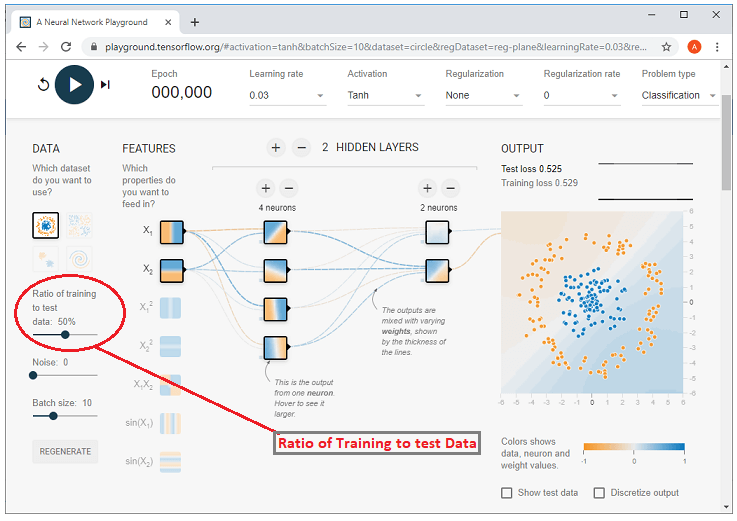
Ví dụ: Nếu nó là 50%, các dấu chấm giống như nó vì đó là cài đặt mặc định của nó, nhưng nếu chúng ta thay đổi điều khiển để tạo ra 10% đó. Sau đó, chúng ta có thể thấy rằng các chấm ở đó trở nên nhỏ hơn nhiều như hình đã cho.

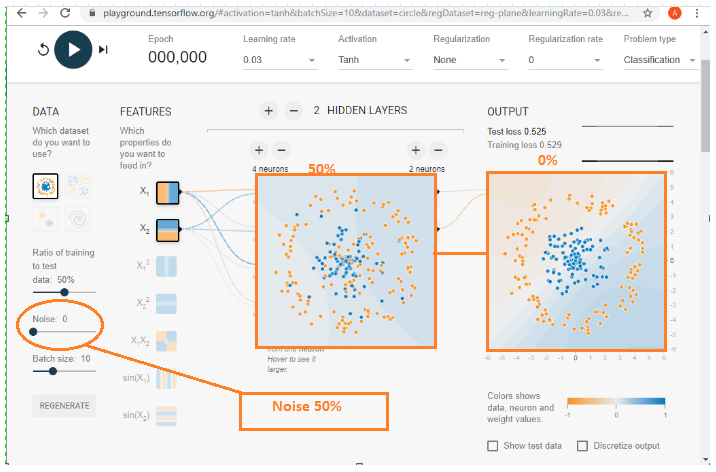
Mức độ tiếng ồn của tập dữ liệu có thể được kiểm soát. Chúng tôi có thể làm điều đó bằng cách sử dụng mô-đun điều khiển. Mẫu dữ liệu trở nên không đáng tin cậy hơn khi nhiễu tăng lên. Khi nhiễu bằng 0, thì vấn đề được phân biệt rõ ràng trong các vùng của nó. Tuy nhiên, bằng cách vượt quá 50, chúng ta có thể thấy rằng các chấm màu xanh lam và các chấm màu cam bị trộn lẫn vào nhau, và làm cho nó áp đặt để phân bổ.
Kích thước lô xác định tốc độ dữ liệu để sử dụng cho mỗi lần lặp lại đào tạo và chúng tôi kiểm soát điều này theo ảnh chụp màn hình bên dưới. Chúng tôi có thể kiểm soát nó bằng cách sử dụng bên dưới.

Bây giờ, chúng ta cần thực hiện lựa chọn Tính năng. Lựa chọn tính năng sẽ sử dụng x1 và x2 được đưa ra ở đây;
- X1 là giá trị trên trục hoành.
- X2 là giá trị trên trục tung.
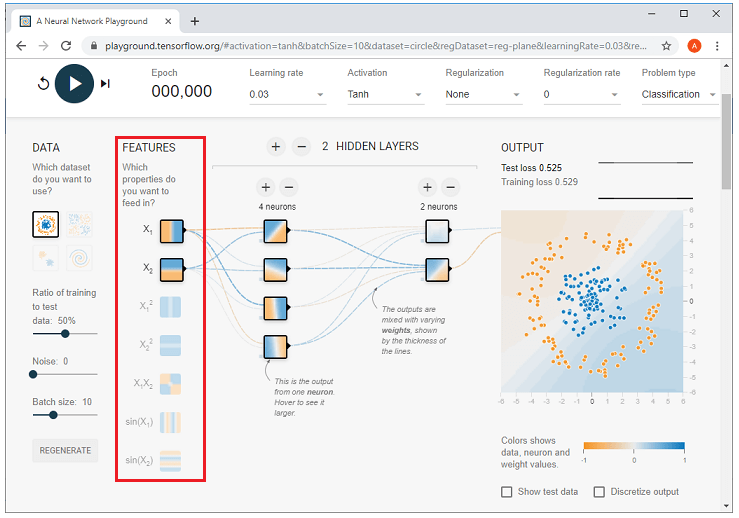
Ví dụ về x1 và x2- Dấu chấm có giá trị x1 là 3,1 và giá trị x2 là 4, như, chúng ta có thể thấy trong sơ đồ dưới đây.

Cấu trúc lớp ẩn được liệt kê bên dưới, nơi chúng ta có thể thiết lập tối đa sáu lớp ẩn. Nếu chúng ta muốn kiểm soát số lượng lớp ẩn bằng cách thêm một lớp ẩn, thì hãy nhấp vào dấu cộng. Và chúng tôi cũng có thể thêm tối đa tám tế bào thần kinh trên mỗi trang ẩn và điều khiển là bằng cách nhấp vào dấu cộng để thêm nơ-ron vào một lớp ẩn.

Bằng cách nhấn nút mũi tên sẽ bắt đầu đào tạo NN (Mạng thần kinh) trong đó Epoch sẽ tăng một và nhân giống ngược được sử dụng để đào tạo mạng thần kinh. Nếu chúng ta cần làm mới phương pháp tổng thể, thì chúng ta có thể làm điều đó bằng cách nhấp vào nút làm mới.

NN (Mạng Nơ-ron) giảm thiểu Thiệt hại và Mất Huấn luyện. Sự thay đổi về Mất kiểm tra và Mất tập luyện sẽ được trình bày trong các đường cong hiệu suất nhỏ nằm ở phía bên phải bên dưới. Thiệt hại sẽ có đường cong hiệu suất màu trắng và Mất tập luyện sẽ có đường cong hiệu suất màu xám. Nếu giảm lỗ, đường cong sẽ đi xuống.

Neural Network Model/ Perceptron
Mô hình mạng nơ-ron hay Perceptron là một mạng lưới các thành phần đơn giản được gọi là các nơ-ron nhận đầu vào, thay đổi trạng thái bên trong của chúng theo dữ liệu. Và sản xuất đầu ra (0 và 1) tùy thuộc vào dữ liệu và kích hoạt. Chúng ta chỉ có một đầu vào và đầu ra, và tốt nhất là một lớp ẩn trong mạng nơ-ron dễ tiếp cận nhất được gọi là mạng nơ-ron nông.
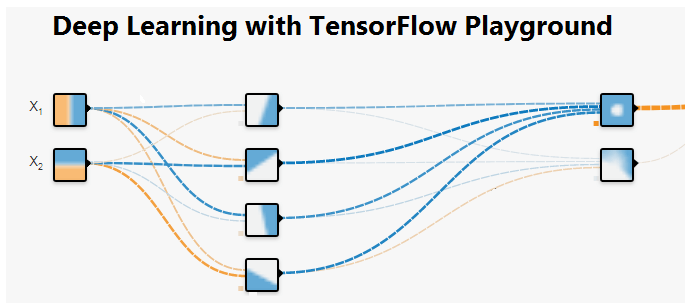
Tất cả các màu đều có ý nghĩa trong Playground
Màu cam và màu xanh lam được sử dụng để hình dung khác nhau, nhưng trong thực tế, màu cam thể hiện các giá trị âm và màu xanh lam hiển thị các giá trị dương.
Các điểm dữ liệu có màu cam hoặc xanh lam, tương ứng với một điểm tích cực và một điểm tiêu cực.
Trong các lớp ẩn, các đường được tô màu bởi trọng lượng của các kết nối giữa các nơ-ron. Màu xanh lam hiển thị trọng lượng thực và màu cam hiển thị trọng lượng âm.
Trong lớp đầu ra, các chấm có màu cam hoặc xanh lam tùy thuộc vào giá trị ban đầu. Màu nền hiển thị những gì mạng đang dự đoán cho một khu vực cụ thể.
Trường hợp sử dụng
Tại sao chúng ta có thể tăng các neurons ở lớp ẩn?
Chúng ta có thể bắt đầu với mô hình cơ bản (Mạng nơron nông) trong một nơron duy nhất trong lớp ẩn. Hãy chọn tập dữ liệu ‘Vòng tròn’, các tính năng ‘X1’ và ‘X2’, tốc độ học tập 0,03 và kích thích ‘ReLU’.
Chúng tôi sẽ nhấn nút chạy và đợi hoàn thành một trăm kỷ nguyên và sau đó nhấp vào ‘tạm dừng.’

Tổn thất trong quá trình huấn luyện và thử nghiệm là hơn 0,4, sau khi hoàn thành 100 kỷ nguyên. Bây giờ chúng ta sẽ thêm bốn nơ-ron trong lớp ẩn bằng cách sử dụng nút thêm và chạy lại.
Bây giờ, mất kiểm tra và đào tạo của chúng tôi khi đó là 0,02 và kết quả đầu ra được phân loại rất tốt trong hai lớp (màu cam và màu xanh lam). Việc bổ sung neural trong lớp ẩn cung cấp sự linh hoạt để ấn định các trọng số khác nhau và tính toán song song. Tuy nhiên, việc bổ sung tế bào thần kinh sau một mức độ nhất định sẽ tốn kém mà ít mang lại lợi ích.
Tại sao chúng tôi sử dụng một hàm kích hoạt phi tuyến tính cho các bài toán phân loại?
Trong mạng nơron, chúng tôi sử dụng các hàm kích hoạt phi tuyến tính cho bài toán phân loại vì nhãn đầu ra của chúng tôi nằm giữa 0 và 1, trong đó hàm kích hoạt tuyến tính có thể cung cấp bất kỳ số nào trong khoảng từ -∞ đến + ∞. Kết quả là đầu ra sẽ không được hội tụ bất cứ lúc nào.

Trong sơ đồ trên, chúng tôi đã chạy cùng một mô hình nhưng kích hoạt tuyến tính, và nó không hội tụ. Hiệu quả kiểm tra và đào tạo là hơn 0,5 sau 100 kỷ nguyên.
Tại sao chúng ta có thể tăng các lớp ẩn trong Playground?
Bây giờ, chúng ta thêm một lớp ẩn nữa với các nơron kép và nhấn nút chạy. Thử nghiệm và độ chính xác của chúng tôi giảm xuống dưới 0,02 chỉ trong 50 kỷ nguyên và gần một nửa so với bất kỳ mô hình lớp ẩn đơn lẻ nào. Và tương tự như các tế bào thần kinh, việc thêm các lớp ẩn sẽ không phải là lựa chọn phù hợp cho mọi trường hợp. Nó trở nên đắt tiền mà không thêm bất kỳ lợi ích nào. Nó được giải thích rất tốt trong hình ảnh. Ngay cả khi chạy 100 epoch, chúng tôi cũng không thể đạt được kết quả tốt.

Tại sao kích hoạt ReLU là một lựa chọn tuyệt vời cho tất cả các lớp ẩn bởi vì đạo hàm là 1 nếu z dương và 0 khi z âm.
Chúng tôi sẽ chạy các chức năng kích hoạt đào tạo khác nhau (ReLU, sigmoid, tanh và tuyến tính) và chúng tôi sẽ thấy tác động.

Tại sao kích hoạt ReLU lại là lựa chọn phù hợp cho các lớp ẩn?
Đơn vị tuyến tính đã chỉnh lưu (ReLU) là một lựa chọn được bầu chọn cho tất cả các lớp ẩn vì đạo hàm của nó là một nếu z là dương và 0 khi z là âm. Theo một cách khác, cả hàm sigmoid và tanh đều không phù hợp với các lớp ẩn vì nếu z là rất lớn hoặc nhỏ. Sau đó, phạm vi của nhiệm vụ trở nên rất nhỏ, điều này sẽ làm chậm lại quá trình giảm dần độ dốc.

Trong hình trên, rõ ràng là ReLU làm tốt hơn tất cả các chức năng kích hoạt khác. Tanh thực hiện rất tốt với tập dữ liệu đã chọn của chúng tôi nhưng không hiệu quả bằng chức năng ReLU. Đây là lý do chính mà ReLU rất phổ biến trong học sâu.
Hành động thêm / bớt hoặc thay đổi bất kỳ tính năng đầu vào nào
Tất cả các tính năng có sẵn không giúp giải quyết vấn đề của mô hình. Việc sử dụng tất cả các tính năng hoặc các tính năng không liên quan sẽ tốn kém và có thể ảnh hưởng đến độ chính xác cuối cùng. Trong các ứng dụng thực tế, cần rất nhiều lần thử và sai để tìm ra phương pháp nào hữu ích nhất cho sự cố.