
Recurrent Neural Networks (RNN) là một loại mạng nơ-ron nhân tạo đặc biệt, được thiết kế để xử lý và dự đoán các dữ liệu có tính chất tuần tự hay chuỗi thời gian. Khác biệt chính giữa RNN và các loại mạng nơ-ron khác nằm ở “bộ nhớ” của nó: RNN có khả năng “nhớ” thông tin từ các đầu vào trước đó, giúp nó có thể xử lý thông tin tuần tự một cách hiệu quả. Điều này được thực hiện qua các chu trình liên kết giữa các nơ-ron, cho phép mạng lưu trữ thông tin trong quá trình xử lý.
RNN đóng một vai trò quan trọng trong nhiều ứng dụng học máy và trí tuệ nhân tạo:
- Xử Lý Ngôn Ngữ Tự Nhiên (NLP): RNN được sử dụng rộng rãi trong các tác vụ như dịch máy, nhận dạng giọng nói, và tạo văn bản tự động. Nó có khả năng hiểu và xử lý ngữ cảnh trong văn bản.
- Dự Đoán Chuỗi Thời Gian: Trong lĩnh vực tài chính và thương mại, RNN được ứng dụng để dự đoán giá cổ phiếu, tỷ giá hối đoái, hoặc để phân tích xu hướng tiêu dùng.
- Phân Tích Âm Nhạc và Video: Nhờ khả năng xử lý dữ liệu tuần tự, RNN có thể được sử dụng để phân tích và tạo ra âm nhạc hoặc video.
Mục tiêu của bài viết này là cung cấp một hướng dẫn chi tiết về cách xây dựng và sử dụng RNN trong TensorFlow, một trong những thư viện học máy và học sâu hàng đầu hiện nay. Bài viết sẽ đi qua các bước từ cơ bản đến nâng cao: từ việc thiết lập môi trường TensorFlow, xây dựng cấu trúc RNN, huấn luyện và tối ưu hóa mô hình, cho đến cách áp dụng mô hình trong các tình huống thực tế. Qua đó, độc giả sẽ có được kiến thức cần thiết để bắt đầu với RNN và khám phá khả năng ứng dụng rộng lớn của nó trong lĩnh vực học sâu.
Định nghĩa Recurrent Neural Network (RNN)
Recurrent Neural Network (RNN) là một loại mạng nơ-ron nhân tạo chủ yếu được sử dụng trong nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên (NLP). RNN được sử dụng trong học tập sâu và trong việc phát triển các mô hình bắt chước hoạt động của các tế bào thần kinh trong não người.
Mạng lặp lại được thiết kế để nhận dạng các mẫu trong chuỗi dữ liệu, chẳng hạn như văn bản, bộ gen, chữ viết tay, lời nói và dữ liệu chuỗi thời gian số phát ra từ cảm biến, thị trường chứng khoán và các cơ quan chính phủ.
Recurrent Neural Network trông tương tự như mạng nơ-ron truyền thống ngoại trừ một trạng thái bộ nhớ được thêm vào các nơ-ron. Việc tính toán là bao gồm một bộ nhớ đơn giản.
Recurrent Neural Network là một loại thuật toán hướng đến học sâu, theo cách tiếp cận tuần tự. Trong mạng nơ-ron, chúng ta luôn giả định rằng mỗi đầu vào và đầu ra phụ thuộc vào tất cả các lớp khác. Các loại mạng nơ-ron này được gọi là mạng tái phát vì chúng thực hiện tuần tự các phép tính toán học.

Làm thế nào để Mạng RNN hoạt động?
Trong mạng Neural RNN, thông tin chuyển qua một vòng lặp đến lớp ẩn giữa.
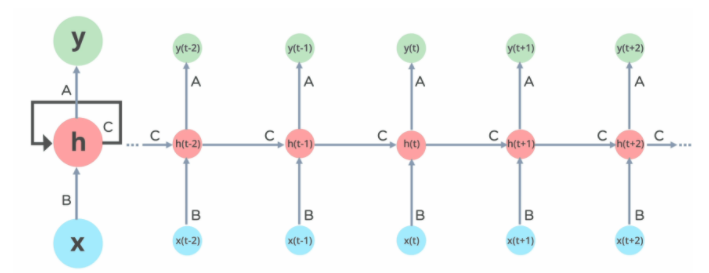
Lớp đầu vào ‘x’ nhận đầu vào cho mạng nơ-ron và xử lý nó và chuyển nó vào lớp giữa.
Lớp giữa ‘h’ có thể bao gồm nhiều lớp ẩn, mỗi lớp có chức năng kích hoạt và trọng số và thành kiến riêng. Nếu bạn có một mạng nơron trong đó các tham số khác nhau của các lớp ẩn khác nhau không bị ảnh hưởng bởi lớp trước đó, tức là: mạng nơron không có bộ nhớ, thì bạn có thể sử dụng mạng nơron tuần hoàn.
RNN sẽ chuẩn hóa các chức năng kích hoạt và trọng số và độ lệch khác nhau để mỗi lớp ẩn có các tham số giống nhau. Sau đó, thay vì tạo nhiều lớp ẩn, nó sẽ tạo một lớp và lặp lại nhiều lần theo yêu cầu.
Cơ Chế “Nhớ” trong RNN:
- RNN được thiết kế để xử lý dữ liệu dạng chuỗi, như văn bản hoặc chuỗi thời gian. Điểm đặc biệt của RNN so với các mạng nơ-ron khác là khả năng “nhớ” thông tin từ các đầu vào trước đó. Điều này được thực hiện thông qua các kết nối hồi tiếp từ đầu ra của một nơ-ron tới đầu vào của nó trong các bước thời gian tiếp theo.
- Trong mỗi bước thời gian, RNN không chỉ xử lý đầu vào mới mà còn tích hợp thông tin đã “học” từ các bước thời gian trước đó.
Luồng Thông Tin trong RNN:
Trong RNN, thông tin di chuyển từ lớp đầu vào qua các lớp ẩn (có thể có nhiều lớp ẩn), rồi đến lớp đầu ra. Khác với các mạng feedforward, trong RNN, thông tin không chỉ di chuyển một chiều từ đầu vào đến đầu ra mà còn được truyền ngược lại qua các chu kỳ.
Ứng dụng của RNN
RNN có nhiều công dụng khi dự đoán tương lai. Trong ngành tài chính, RNN có thể giúp dự đoán giá cổ phiếu hoặc dấu hiệu của xu hướng thị trường chứng khoán (tức là tích cực hoặc tiêu cực).
RNN được sử dụng cho ô tô tự lái vì nó có thể tránh tai nạn ô tô bằng cách đoán trước tuyến đường của xe.
RNN được sử dụng rộng rãi trong chú thích hình ảnh, phân tích văn bản, dịch máy và phân tích tình cảm. Ví dụ, người ta nên sử dụng đánh giá phim để hiểu cảm giác mà khán giả cảm nhận sau khi xem phim. Tự động hóa nhiệm vụ này rất hữu ích khi công ty điện ảnh không thể có nhiều thời gian hơn để xem xét, củng cố, dán nhãn và phân tích các bài đánh giá. Máy có thể thực hiện công việc với mức độ chính xác cao hơn.
Sau đây là các ứng dụng của RNN:
- Machine Translation
Chúng tôi sử dụng Mạng thần kinh tái tạo trong công cụ dịch để dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác. Họ làm điều này với sự kết hợp của các mô hình khác như LSTM (Bộ nhớ ngắn hạn dài) s.
- Speech Recognition
Mạng thần kinh tái tạo đã thay thế các mô hình nhận dạng giọng nói truyền thống sử dụng Mô hình Markov ẩn. Các Mạng thần kinh lặp lại này, cùng với LSTM, sẵn sàng tốt hơn trong việc phân loại các bài phát biểu và chuyển đổi chúng thành văn bản mà không làm mất ngữ cảnh.

- Sentiment Analysis
Chúng tôi sử dụng phân tích tình cảm để xác định tính tích cực, tiêu cực hoặc tính trung lập của câu. Vì vậy, RNNs là những người thành thạo nhất trong việc xử lý dữ liệu tuần tự để tìm ra ý của câu.

- Automatic Image Tagger
RNN, kết hợp với mạng nơ-ron phức hợp, có thể phát hiện hình ảnh và cung cấp mô tả của chúng dưới dạng thẻ. Ví dụ: hình ảnh con cáo nhảy qua hàng rào được giải thích phù hợp hơn bằng cách sử dụng RNN.

Các loại RNN
Lý do chính khiến các mạng lặp lại thú vị hơn là chúng cho phép chúng ta hoạt động trên các chuỗi vectơ: Trình tự trong đầu vào, đầu ra hoặc trong trường hợp chung nhất là cả hai. Một vài ví dụ có thể cụ thể hơn:

Mỗi hình chữ nhật trong hình trên đại diện cho các vectơ và các mũi tên đại diện cho các hàm. Vectơ đầu vào có màu Đỏ, vectơ đầu ra có màu xanh lam và màu xanh lá cây giữ trạng thái của RNN.
One-to-one:
Đây còn được gọi là mạng Neural thuần túy. Nó xử lý một kích thước cố định của đầu vào với kích thước cố định của đầu ra, nơi chúng độc lập với thông tin / đầu ra trước đó.
Ví dụ: Phân loại ảnh.
One-to-Many:
Nó xử lý một kích thước cố định của thông tin làm đầu vào cung cấp một chuỗi dữ liệu làm đầu ra.
Ví dụ: Image Captioning lấy hình ảnh làm đầu vào và đầu ra một câu từ.
Many-to-One:
Nó lấy một chuỗi thông tin làm đầu vào và đầu ra với kích thước cố định của đầu ra.
Ví dụ: phân tích tình cảm trong đó bất kỳ câu nào được phân loại là thể hiện tình cảm tích cực hoặc tiêu cực.
Many-to-Many:
Nó lấy Chuỗi thông tin làm đầu vào và xử lý các đầu ra lặp lại dưới dạng Chuỗi dữ liệu.
Ví dụ: Dịch máy, trong đó RNN đọc bất kỳ câu nào bằng tiếng Anh và sau đó xuất ra câu đó bằng tiếng Pháp.
Bidirectional Many-to-Many
Đầu vào và đầu ra trình tự được đồng bộ hóa. Lưu ý rằng trong mọi trường hợp không có ràng buộc nào được chỉ định trước đối với trình tự độ dài bởi vì phép biến đổi lặp lại (màu xanh lá cây) là cố định và có thể được áp dụng nhiều lần tùy thích.
Hạn chế của RNN
RNN có nhiệm vụ đưa thông tin kịp thời. Tuy nhiên, việc tuyên truyền tất cả các thông tin này là một việc khá khó khăn khi bước thời gian quá dài. Khi một mạng có quá nhiều lớp sâu, nó sẽ trở nên không thể kiểm tra được. Vấn đề này được gọi là: vấn đề gradient biến mất.
Nếu chúng ta nhớ, mạng nơ-ron cập nhật việc sử dụng trọng số của thuật toán giảm độ dốc. Gradient nhỏ dần khi mạng tiến xuống các lớp thấp hơn.
Gradient không đổi, có nghĩa là không có không gian để cải thiện. Mô hình học hỏi từ sự thay đổi trong gradient của nó; sự thay đổi này ảnh hưởng đến đầu ra của mạng. Nếu sự khác biệt trong gradient quá nhỏ (tức là trọng lượng thay đổi một chút), hệ thống không thể học được bất cứ điều gì và do đó, kết quả đầu ra. Do đó, một hệ thống đối mặt với vấn đề gradient biến mất không thể hội tụ về giải pháp phù hợp.
Neural tái diễn sẽ thực hiện như sau.
Mạng lặp lại đầu tiên thực hiện việc chuyển đổi các kích hoạt độc lập thành các kích hoạt phụ thuộc. Nó cũng chỉ định cùng một trọng số và độ lệch cho tất cả các lớp, điều này làm giảm độ phức tạp của RNN của các tham số. Và nó cung cấp một nền tảng tiêu chuẩn để ghi nhớ các kết quả đầu ra trước đó bằng cách cung cấp đầu ra trước đó làm đầu vào cho lớp tiếp theo.
Ba lớp này có cùng trọng số và độ lệch, kết hợp thành một đơn vị lặp lại duy nhất.
Để tính toán trạng thái hiện tại-
- ht = f (ht-1, Xt)
- Trong đó ht = trạng thái hiện tại
- Ht-1 = trạng thái trước đó
- Xt = trạng thái đầu vào
Để áp dụng hàm kích hoạt tanh, chúng ta có-
ht = tanh (Whhht-1 + WxhXt)
Ở đâu:
- Whh = trọng lượng của nơ-ron Recurrent và,
- Wxh = trọng lượng của nơ-ron đầu vào
Công thức tính sản lượng:
Yt = Whyht
Đào tạo thông qua RNN
- Mạng thực hiện một bước thời gian duy nhất của đầu vào.
- Chúng ta có thể tính toán trạng thái hiện tại thông qua đầu vào hiện tại và trạng thái trước đó.
- Bây giờ, trạng thái hiện tại thông qua ht-1 cho trạng thái tiếp theo.
- Có n số bước, và cuối cùng, tất cả thông tin có thể là j
- có dầu.
- Sau khi hoàn thành tất cả các bước, bước cuối cùng là tính toán sản lượng.
- Cuối cùng, chúng tôi tính toán sai số bằng cách tính toán sự khác biệt giữa sản lượng thực tế và sản lượng dự đoán.
- Lỗi được truyền ngược vào mạng để điều chỉnh trọng số và tạo ra kết quả tốt hơn.

