
Long short-term memory (LSTM) là một kiến trúc artificial recurrent neural network (RNN) được sử dụng trong lĩnh vực Deep learning. Nó được đề xuất vào năm 1997 bởi Sepp Hochreiter và Jurgen schmidhuber. Không giống như các feed-forward neural networks, LSTM có các kết nối phản hồi. Nó có thể xử lý không chỉ các điểm dữ liệu đơn lẻ (chẳng hạn như hình ảnh) mà còn toàn bộ chuỗi dữ liệu (chẳng hạn như speech hoặc video).
Các bài viết liên quan:
Ví dụ: LSTM là một ứng dụng cho các tác vụ như nhận dạng chữ viết tay không được phân đoạn, được kết nối hoặc nhận dạng giọng nói.
Một đơn vị LSTM chung bao gồm một cell, một input gate, một output gate và một forget gate. Cell ghi nhớ các giá trị trong khoảng thời gian tùy ý và ba gate điều chỉnh luồng thông tin input và output. LSTM rất phù hợp để classify, process, và predict có khoảng thời gian không xác định.
Mạng Long short-term memory (LSTM) là một phiên bản sửa đổi của mạng nơ-ron tuần hoàn, giúp dễ dàng ghi nhớ dữ liệu quá khứ trong bộ nhớ.
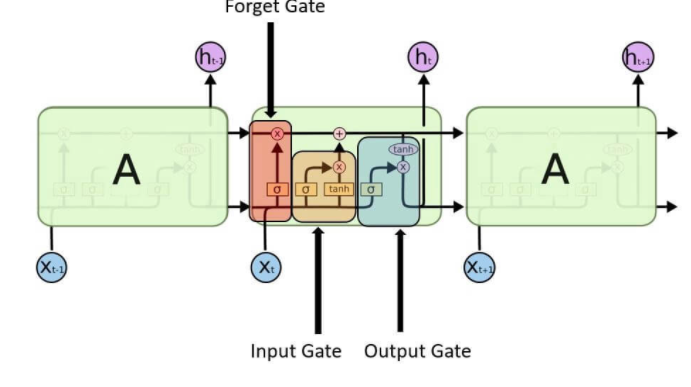
Input gate– Nó phát hiện ra giá trị nào từ đầu vào sẽ được sử dụng để sửa đổi bộ nhớ. Hàm Sigmoid quyết định giá trị nào sẽ cho qua 0 hoặc 1. Và hàm tanh đưa ra trọng số cho các giá trị được truyền, quyết định mức độ quan trọng của chúng trong khoảng từ -1 đến 1.
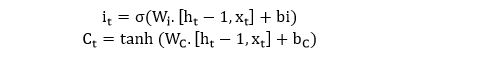
Forget gate– Nó khám phá các chi tiết cần loại bỏ khỏi khối. Một hàm sigmoid quyết định nó. Nó xem xét trạng thái trước đó (ht-1) và đầu vào nội dung (Xt) và xuất ra một số giữa 0 (bỏ qua điều này) và 1 (giữ nguyên điều này) cho mỗi số trong trạng thái ô Ct-1.
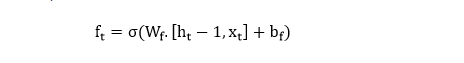
Output gate – Đầu vào và bộ nhớ của khối được sử dụng để quyết định đầu ra. Hàm Sigmoid quyết định giá trị nào cho qua 0 hoặc 1. Và hàm tanh quyết định giá trị nào cho qua 0, 1. Và hàm tanh đưa ra trọng số cho các giá trị được truyền, quyết định mức độ quan trọng của chúng trong khoảng từ -1 đến 1 và nhân lên với đầu ra là sigmoid.

Nó đại diện cho một ô RNN đầy đủ lấy đầu vào hiện tại của chuỗi xi và xuất ra trạng thái ẩn hiện tại, xin chào, chuyển điều này đến ô RNN tiếp theo cho chuỗi đầu vào của chúng ta. Bên trong ô LSTM phức tạp hơn rất nhiều so với ô RNN truyền thống, trong khi ô RNN thông thường có một “lớp bên trong” duy nhất hoạt động trên trạng thái hiện tại (ht-1) và đầu vào (xt).
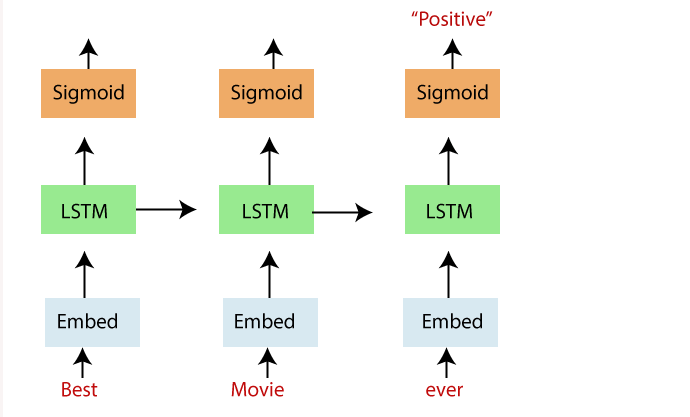
Trong sơ đồ trên, chúng ta thấy một mạng LSTM “chưa được cuộn” với một lớp nhúng, một lớp LSTM tiếp theo và một chức năng kích hoạt sigmoid. Chúng tôi nhận ra rằng đầu vào của chúng tôi, trong trường hợp này, các từ trong bài đánh giá phim, được nhập theo trình tự.
Các từ được nhập vào một tra cứu nhúng. Trong hầu hết các trường hợp, khi làm việc với một kho dữ liệu văn bản, kích thước của từ vựng lớn bất thường.
Đây là một biểu diễn đa chiều, phân tán của các từ trong không gian vectơ. Những cách nhúng này có thể được học bằng cách sử dụng các kỹ thuật học sâu khác như word2vec, chúng tôi có thể đào tạo mô hình theo kiểu end-to-end để xác định cách nhúng khi chúng tôi dạy.
Sau đó, các nhúng này được nhập vào lớp LSTM của chúng tôi, nơi đầu ra được đưa đến lớp đầu ra sigmoid và ô LSTM cho từ tiếp theo trong trình tự của chúng tôi.
Lớp LSTM
Chúng tôi sẽ thiết lập một chức năng để xây dựng các lớp LSTM để xử lý số lượng các lớp và kích thước một cách linh hoạt. Dịch vụ sẽ lấy một danh sách các kích thước LSTM, có thể cho biết số lượng các lớp LSTM dựa trên độ dài của danh sách (ví dụ: ví dụ của chúng tôi sẽ sử dụng danh sách có độ dài 2, chứa các kích thước 128 và 64, cho biết mạng LSTM hai lớp trong đó kích thước lớp đầu tiên là 128 và lớp thứ hai có kích thước lớp ẩn là 64).
def build_lstm_layers(lstm_sizes, embed, keep_prob_, batch_size):
"""
Create the LSTM layers
"""
lstms = [tf.contrib.rnn.BasicLSTMCell(size) for size in lstm_sizes]
# Add dropout to the cell
drops = [tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob_) for lstm in lstms]
# Stacking up multiple LSTM layers, for deep learning
cell = tf.contrib.rnn.MultiRNNCell(drops)
# Getting an initial state of all zeros
initial_state = cell.zero_state(batch_size, tf.float32)
lstm_outputs, final_state = tf.nn.dynamic_rnn(cell, embed, initial_state=initial_state)
Sau đó, danh sách các LSTM đã bỏ qua được bao bọc sẽ được chuyển đến một ô TensorFlow MultiRNN để xếp chồng các lớp lại với nhau.
Loss function, optimizer và accuracy
Cuối cùng, chúng tôi tạo các hàm để xác định chức năng mất mô hình, trình tối ưu hóa và độ chính xác của chúng tôi. Mặc dù tổn thất và độ chính xác chỉ được tính toán dựa trên kết quả, nhưng Trong TensorFlow mọi thứ đều là một phần của biểu đồ tính toán.
def build_cost_fn_and_opt(lstm_outputs, labels_, learning_rate):
"""
Creating the Loss function and Optimizer
"""
predictions = tf.contrib.layers.fully_connected(lstm_outputs[:, -1], 1, activation_fn=tf.sigmoid)
loss = tf.losses.mean_squared_error(labels_, predictions)
optimzer = tf.train.AdadeltaOptimizer (learning_rate).minimize(loss)
def build_accuracy(predictions, labels_):
"""
Create accuracy
"""
correct_pred = tf.equal(tf.cast(tf.round(predictions), tf.int32), labels_)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) Xây dựng graph và training
Đầu tiên, chúng tôi gọi từng hàm mà chúng tôi đã xác định để xây dựng mạng và gọi một phiên TensorFlow để huấn luyện mô hình trên một số kỷ nguyên được xác định trước bằng cách sử dụng các lô nhỏ. Vào cuối mỗi kỷ nguyên, chúng tôi sẽ in độ mất mát, độ chính xác của quá trình đào tạo và độ chính xác của việc xác nhận để theo dõi kết quả khi chúng tôi đào tạo mô hình.
def build_and_train_network(lstm_sizes, vocab_size, embed_size, epochs, batch_size,
learning_rate, keep_prob, train_x, val_x, train_y, val_y):
# Build Graph
with tf.Session() as sess:
# Train Network
# Save Network Tiếp theo, chúng tôi xác định các siêu tham số mô hình của chúng tôi và chúng tôi sẽ xây dựng một mạng LSTM hai lớp với kích thước lớp ẩn lần lượt là 128 và 64.
Khi mô hình được đào tạo xong, chúng tôi sử dụng trình tiết kiệm TensorFlow để lưu các tham số mô hình để sử dụng sau này.
Thử nghiệm
Cuối cùng, chúng tôi kiểm tra kết quả mô hình của chúng tôi trên bộ thử nghiệm để đảm bảo chúng phù hợp với những gì chúng tôi quan sát được trong quá trình đào tạo.
def test_network(model_dir, batch_size, test_x, test_y):
# Build Network
with tf.Session() as sess:
# Restore Model
# Test Model Độ chính xác của bài kiểm tra là 72%. Điều này phù hợp với độ chính xác xác thực của chúng tôi và chỉ ra rằng chúng tôi đã nắm bắt trong một phân phối dữ liệu thích hợp trong quá trình phân tách dữ liệu của chúng tôi.

Những câu hỏi phổ biến về Long short-term memory (LSTM)
Các câu hỏi phổ biến về Long short-term memory (LSTM) bao gồm:
- LSTM là gì?
- LSTM là một kiến trúc mạng nơ-ron tái phát (recurrent neural network) được thiết kế để xử lý các chuỗi dữ liệu có độ dài lớn và khó khăn trong việc giữ lại thông tin lâu dài.
- LSTM được sử dụng để làm gì?
- LSTM được sử dụng để xử lý các chuỗi dữ liệu như văn bản, âm thanh, hình ảnh và video, và có thể được áp dụng trong các lĩnh vực như xử lý ngôn ngữ tự nhiên, nhận dạng giọng nói, dịch máy, v.v.
- LSTM khác gì so với các mô hình mạng nơ-ron khác?
- LSTM có khả năng lưu trữ thông tin lâu dài và xử lý các chuỗi dữ liệu dài và phức tạp hơn so với các kiến trúc mạng nơ-ron tái phát khác như mạng Elman hay mạng Jordan.
- Các thành phần chính của LSTM là gì?
- Các thành phần chính của LSTM bao gồm cổng quên (forget gate), cổng đầu vào (input gate), cổng đầu ra (output gate) và tế bào trạng thái (cell state).
- Các cổng của LSTM làm gì?
- Cổng quên (forget gate) quyết định thông tin nào sẽ được lưu trữ và thông tin nào sẽ bị xóa; cổng đầu vào (input gate) quyết định thông tin mới nào sẽ được lưu trữ vào tế bào trạng thái; cổng đầu ra (output gate) quyết định thông tin nào sẽ được truyền đi và tế bào trạng thái (cell state) là nơi lưu trữ thông tin lâu dài.
- LSTM có những ứng dụng nào trong xử lý ngôn ngữ tự nhiên?
- LSTM được sử dụng để giải quyết các vấn đề trong xử lý ngôn ngữ tự nhiên như: phân loại văn bản, dịch máy, sinh văn bản tự động, tổng hợp giọng nói, và xử lý dữ liệu ngôn ngữ tự nhiên khác.
- LSTM có những ứng dụng nào trong xử lý âm thanh và hình ảnh?
- LSTM có thể được sử dụng để giải quyết các vấn đề trong xử lý âm thanh và hình ảnh như: nhận dạng giọng nói dạng (voice recognition), phân loại hình ảnh, nhận diện khuôn mặt, phát hiện đối tượng và các ứng dụng khác trong lĩnh vực thị giác máy tính.
- LSTM có nhược điểm gì?
- Một trong những nhược điểm của LSTM là việc đào tạo mô hình có thể tốn nhiều thời gian và tài nguyên tính toán. Ngoài ra, cũng có thể xảy ra hiện tượng quá khớp (overfitting) nếu không sử dụng các kỹ thuật chính quy hóa (regularization).
- LSTM được triển khai như thế nào?
- LSTM có thể được triển khai bằng cách sử dụng các thư viện và framework của mạng nơ-ron như Keras, TensorFlow, PyTorch, v.v. Các công cụ này giúp cho việc xây dựng, đào tạo và triển khai mô hình LSTM trở nên đơn giản và dễ dàng hơn.
- Làm thế nào để tối ưu hóa mô hình LSTM?
- Để tối ưu hóa mô hình LSTM, có thể sử dụng các kỹ thuật như thuật toán tối ưu Adam, giảm tỷ lệ học tập (learning rate decay), sử dụng kỹ thuật dropout và chính quy hóa L2 (L2 regularization). Ngoài ra, việc điều chỉnh các siêu tham số như số lớp LSTM, số đơn vị ẩn, số lượng epoch, v.v. cũng có thể giúp tăng độ chính xác và hiệu suất của mô hình LSTM.

