
Bây giờ, trong loạt bài hướng dẫn về R websitehcm, chúng ta sẽ tìm hiểu cách machine learning giúp lập trình R như thế nào. Trong bài viết này, chúng ta sẽ thấy các công cụ và phương tiện khác nhau được cung cấp cho các hoạt động của Machine Learning trong R. Chúng ta cũng sẽ thảo luận về một số gói quan trọng như MICE, caret, e1071 và nhiều gói khác.

Machine learning và R
Machine learning là bước quan trọng nhất trong Khoa học dữ liệu. R cung cấp nhiều phương tiện machine learning khác nhau cho người dùng. Chúng ta sẽ thảo luận về một số thư viện quan trọng. Hơn nữa, chúng tôi sẽ triển khai các gói này trong mã ví dụ R của chúng tôi. Bây giờ chúng ta hãy đi sâu vào các công cụ machine learning quan trọng cho ngôn ngữ lập trình R.
Các bài viết liên quan:
Tìm hiểu sâu hơn về hơn 370 bài hướng dẫn về Khoa học dữ liệu và làm chủ công nghệ
Các công cụ machine learning quan trọng cho R
Mice
MICE là viết tắt của Multivariate Imputation via Chained Sequences . Trong khi xử lý tập dữ liệu, luôn có khả năng dữ liệu bị nhiễm vào vấn đề thiếu giá trị. Trong những trường hợp như vậy, MICE có thể được sử dụng để xác định các giá trị còn thiếu với sự trợ giúp của nhiều kỹ thuật.
MICE_data <- data.frame(var1=rnorm(20,0,1), var2=rnorm(20,5,1)) > MICE_data[c(2,5,7,10),1] <- NA > MICE_data[c(4,8,19),2] <- NA > summary(MICE_data)
Đầu ra:
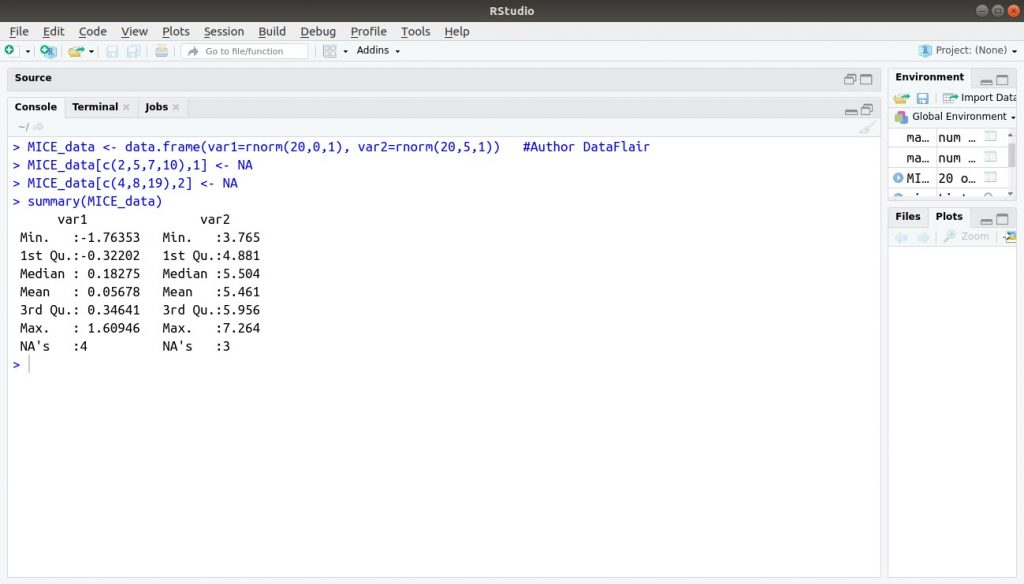
> require(mice) > nice_dataset <- mice(MICE_data)
Đầu ra:

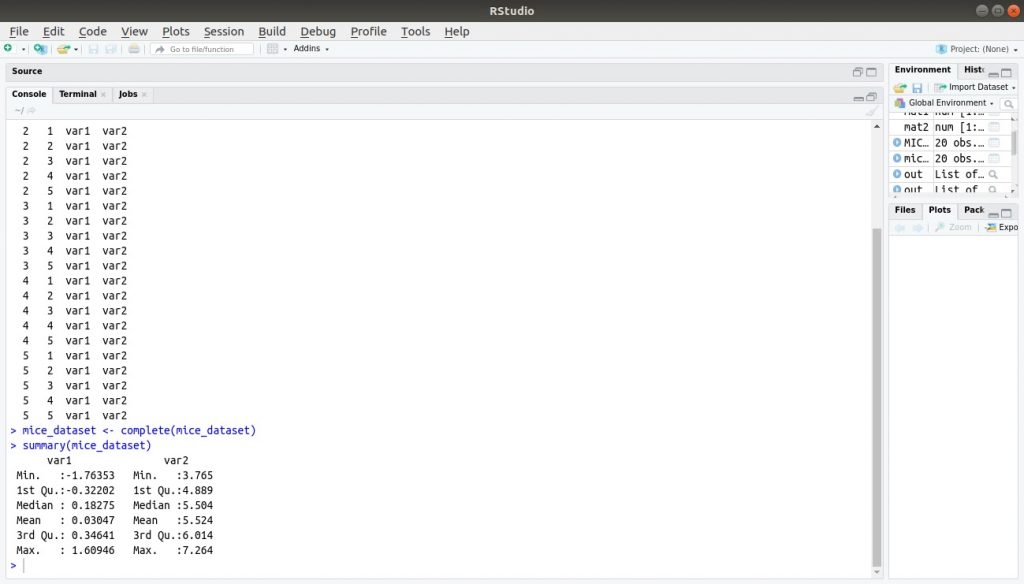
>mice_dataset <- complete(mice_dataset) >summary(mice_dataset)
Đầu ra:
rpart
Sử dụng gói rpart là để thực hiện phân vùng đệ quy trong phân loại, hồi quy và các cây tồn tại. Thủ tục rpart thực hiện điều này trong hai bước. Kết quả là một cây nhị phân. Chúng tôi gọi hàm plot () để vẽ biểu đồ kết quả mà gói rpart tạo ra. Để hiểu phương sai ảnh hưởng đến các biến phụ thuộc dựa trên các biến độc lập, chúng ta sử dụng hàm rpart.
Với sự trợ giúp của rpart, người ta có thể thực hiện cả hai phép hồi quy cũng như phân loại. Hãy để chúng tôi hiểu về hàm rpart với sự trợ giúp của tập dữ liệu iris:
> library(rpart)
> data("iris")
> rpart_fit <- rpart(formula = Species~., data=iris, method = 'class')
> library(rpart.plot)
> summary(rpart_fit)Đầu ra:

> rpart. âm mưu ( rpart_fit )
Đầu ra:

randomForest
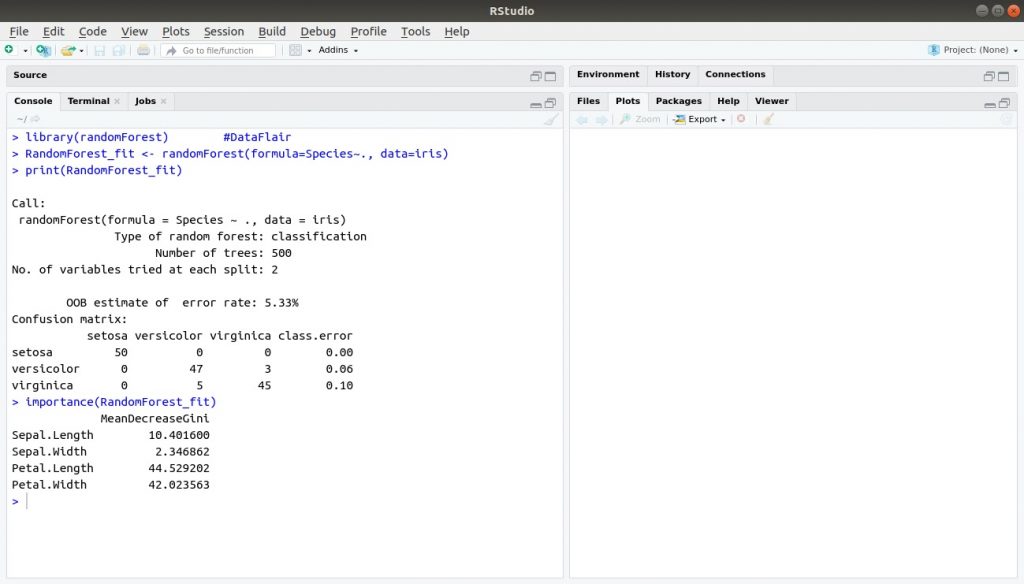
randomForest là thuật toán được sử dụng rộng rãi nhất trong machine learning. Sử dụng randomForest là tạo ra một số lượng lớn các cây quyết định. Cây quyết định tạo ra đầu ra chung được coi là đầu ra cuối cùng.
> library(randomForest) > RandomForest_fit <- randomForest(formula=Species~., data=iris) > print(RandomForest_fit) > importance(RandomForest_fit)
Đầu ra:
Tìm hiểu cách triển khai các thuật toán machine learning trong một dự án thực tế – Phát hiện gian lận thẻ tín dụng với công nghệ máy học trong R
caret
caret đề cập đến Đào tạo Phân loại và Hồi quy . Nó được phát triển để tạo điều kiện cho mô hình dự đoán hiệu quả. Với sự trợ giúp của caret, bạn có thể tìm thấy các thông số tối ưu với các thí nghiệm được kiểm soát trong tự nhiên. Một số công cụ mà gói này cung cấp là:
- Xử lý trước dữ liệu
- Tách dữ liệu
- Điều chỉnh mô hình
- Lựa chọn tính năng
Bây giờ chúng ta hãy xem một ví dụ để triển khai gói caret:
> library(caret) > lm_fit <- train(Sepal.Length~Sepal.Width + Petal.Length + Petal.Width, data=iris, method = "lm") > summary(lm_fit)
Đầu ra:

e1071
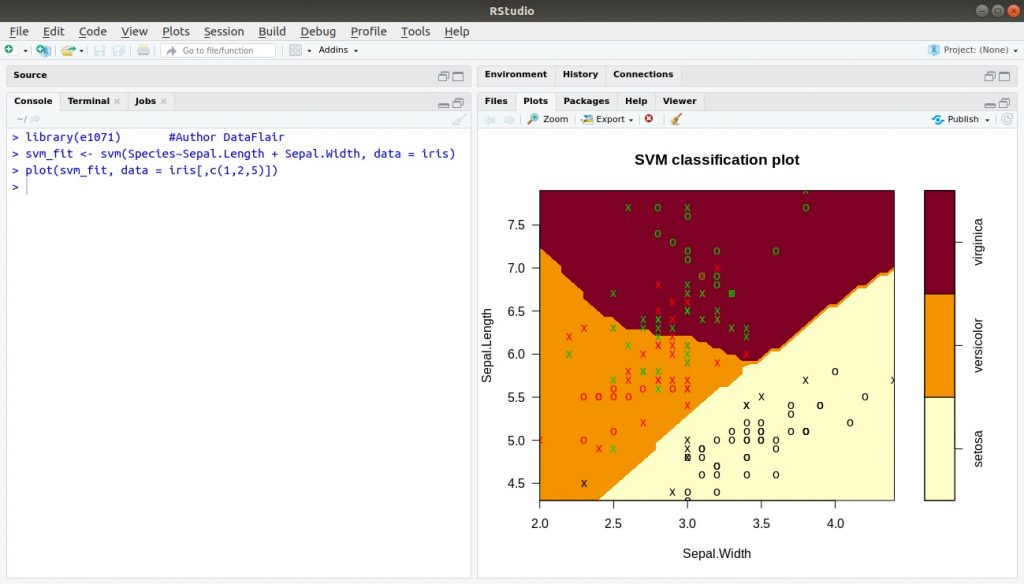
Với sự trợ giúp của e1071 , bạn có thể triển khai Naive Bayes, Fourier Transform, Hỗ trợ Vector Machines, Bagged Clustering, v.v. Hỗ trợ Vector Machines là tính năng quan trọng nhất được cung cấp bởi e1071 cho phép bạn làm việc trên dữ liệu không thể tách rời trên và yêu cầu bạn làm việc trên các thứ nguyên cao hơn để thực hiện phân loại hoặc hồi quy.
> library(e1071) > svm_fit <- svm(Species~Sepal.Length + Sepal.Width, data = iris) > plot(svm_fit, data = iris[,c(1,2,5)])
Đầu ra:
nnet
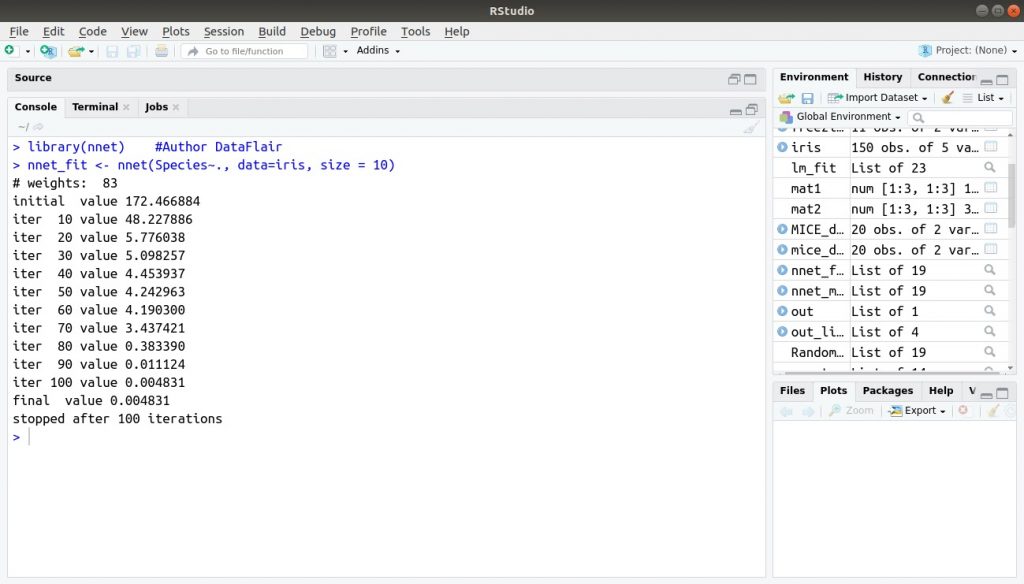
Để triển khai mạng nơron trong R, chúng tôi sử dụng gói nnet. Giới hạn của gói này chỉ là một lớp nút. Nnet sử dụng Mạng thần kinh nhân tạo được mô phỏng theo hệ thần kinh của con người. Chúng ta có thể triển khai mạng nơron trong R như sau:
> library(nnet) > nnet_fit <- nnet(Species~., data=iris, size = 10)
Đầu ra:
Bản tóm tắt
Đến đây là phần cuối của hướng dẫn về machine learning cho R. Trong bài viết này, chúng ta đã thấy cách machine learning nắm giữ một số lượng đáng kể các gói trong R. Chúng ta đã xem qua sáu gói quan trọng sẽ cho phép bạn triển khai nhiều cách phân loại và các thuật toán hồi quy.
Bây giờ, đã đến lúc biết tầm quan trọng của R đối với Khoa học dữ liệu

